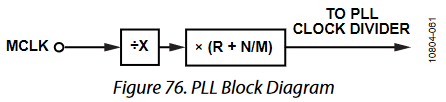
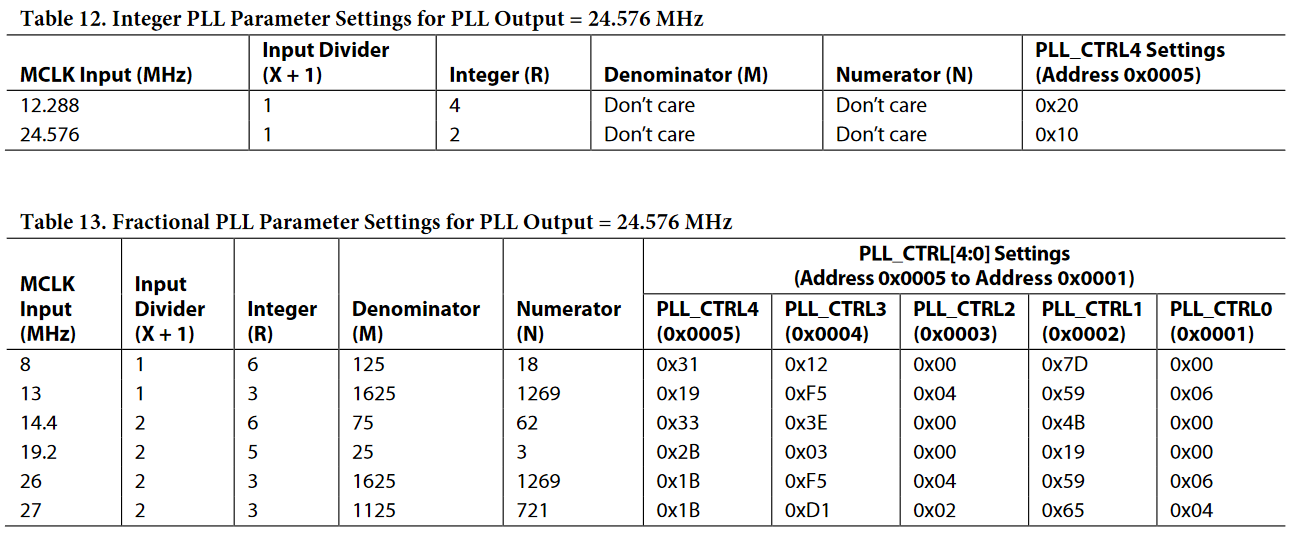
One of the least used but potentially most useful features of the C
preprocessor is the ANSI-specified #error
directive. Here's a look at a couple of clever uses for
#error that have proven invaluable in embedded software
development.
The <writer supplied error message> can consist of
any printable text. You don't even have to enclose the text in quotes.
(Technically, the message is optional--though it rarely makes sense to
omit it.)
When the C preprocessor encounters a #error statement,
it causes compilation to terminate and the writer-supplied error message
to be printed to stderr (link is
external). A typical error message from a C compiler looks like
this:
where Filename is the source file name, line_number is
the line number where the #error statement is located, and
Ennnn is a compiler-specific error number. Thus, the
#error message is basically indistinguishable from ordinary
compiler error messages.
"Wait a minute," you might say. "I spend enough time trying to get
code to compile and now he wants me to do something that causes more
compiler errors?" Absolutely! The essential point is that code that
compiles but is incorrect is worse than useless. I've found three
general areas in which this problem can arise and #error
can help. Read on and see if you agree with me.
Incomplete code
I tend to code using a step-wise refinement approach, so it isn't
unusual during development for me to have functions that do nothing, for
loops that lack a body, and so forth. Consequently, I often have files
that are compilable but lack some essential functionality. Working this
way is fine, until I'm pulled off to work on something else (an
occupational hazard of being in the consulting business). Because these
distractions can occasionally run into weeks, I sometimes return to the
job with my memory a little hazy about what I haven't completed. In the
worst-case scenario (which has occurred), I perform a make, which runs
happily, and then I attempt to use the code. The program, of course,
crashes and burns, and I'm left wondering where to start.
In the past, I'd comment the file to note what had been done and what
was still needed. However, I found this approach to be rather weak
because I then had to read all my comments (and I comment heavily) in
order to find what I was looking for. Now I simply enter something like
the following in an appropriate place in the file:
1
#error *** Nigel - Function incomplete. Fix before using ***
Thus, if I forget that I haven't done the necessary work, an
inadvertent attempt to use the file will result in just about the most
meaningful compiler message I'll ever receive. Furthermore, it saves me
from having to wade through pages of comments, trying to find what work
I haven't finished.
Compiler-dependent code
As much as I strive to write portable code, I often find myself
having to trade off performance for portability - and in the embedded
world, performance tends to win. However, what happens if a few years
later I reuse some code without remembering that the code has
compiler-specific peculiarities? The result is
a much longer debug session than is necessary. But a
judicious#error statement can
prevent a lot of grief. A couple of examples may help.
Example 1
Some floating-point code requires at least 12 digits of resolution to
return the correct results. Accordingly, the various variables are
defined as type long double. But ISO C only
requires that a long double have 10 digits of
resolution. Thus on certain machines, a long double may be
inadequate to do the job. To protect against
this, I would include the following:
1 2 3 4 5
#include <float.h> #if (LDBL_DIG < 12) #error *** long doubles need 12 digit resolution. Do not use this compiler! *** #endif
This approach works by examining the value of an ANSI-mandated
constant found in float.h
(link is external).
Example 2
An amazing amount of code makes invalid assumptions about the
underlying size of the various integer types. If you have code that has
to use an int (as opposed to a user-specified data type such as
int16), and the code assumes that an int is 16 bits, you
can do the following:
1 2 3 4 5
#include <limits.h> #if (INT_MAX != 32767) #error *** This file only works with 16-bit int. Do not use this compiler! *** #endif
Again, this works by checking the value of an ANSI-mandated constant.
This time the constant is found in the file limits.h (link is
external). This approach is a lot more useful than putting these
limitations inside a big comment that someone may or may not read. After
all, you have to read the compiler error messages.
Conditionally-compiled code
Since conditionally compiled code seems to be a necessary evil in
embedded programming, it's common to find code sequences such as the
following:
1 2 3 4 5
#if defined OPT_1 /* Do option_1 */ #else /* Do option_2 */ #endif
As it is written, this code means the following: if and only if OPT_1
is defined, we will do option_1; otherwise we'll do option_2. The
problem with this code is that a user of the code doesn't know (without
explicitly examining the code) that OPT_1 is a valid compiler switch.
Instead, the naive user will simply compile the code without defining
OPT_1 and get the alternate implementation, irrespective of whether that
is what's required or not. A more considerate coder might be aware of
this problem, and instead do the following:
1 2 3 4 5
#if defined OPT_1 /* Do option 1 */ #elif defined OPT_2 /* Do option 2*/ #endif
In this case, failure to define either OPT_1 or OPT_2 will typically
result in an obscure compiler error at a point later in the code. The
user of this code will then be stuck with trying to work out what must
be done to get the module to compile. This is where #error comes in.
Consider the following code sequence:
1 2 3 4 5 6 7
#if defined OPT_1 /* Do option_1 */ #elif defined OPT_2 /* Do option_2 */ #else #error *** You must define one of OPT_1 or OPT_2 *** #endif
Now the compilation fails, but at least it tells the user explicitly
what to do to make the module compile. I know that if this procedure had
been adopted universally, I would have saved a lot of time over the
years trying to reuse other people's code.
So there you have it. Now tell me, don't you agree that
#error is a really useful part of the preprocessor, worthy
of your frequent use-and occasional praise?
NPM
(Node Package Manager) is the default package manager
employed in JavaScript runtime environment in Node.js. It has a very
frequently used command npm install [Package Name]
–save. But the fact is there is no difference between
npm install [Package Name] and npm install
[Package Name] –save in the later version after npm 5.0.0
onwards.
Before npm 5.0.0, it was necessary to add --save after
package name because it will save the installed package to package.json
file in the dependency section. If you are using a recent version of npm
save yourself from unnecessary typing and use npm install
[Package Name] instead of npm install [Package Name]
--save by default it will add the installed
package to the dependency list in the package.json file.
NPM has several commands which are listed below:
–save or -S:
When the following command is used with npm install this will save
all your installed core packages into the dependency section in the
package.json file. Core dependencies are those packages without which
your application will not give desired results. But as mentioned
earlier, it is an unnecessary feature in the npm 5.0.0 version
onwards.
1
npm install --save
–save-prod or -P:
The following command is introduced in the later version of npm it
will perform the same task as the
1
--save
command unless any other command such as
1
-D
or
1
-O
is present.
1
npm install --save-prod
–save-dev or -D:
With
1
--save-dev
or
1
-D
command your installed packages will be added to devDependency
section of the package.json file. Development dependencies are those
packages which only meant for development purpose it will not affect the
application’s result.
1
npm install --save-dev
–save-optional or -O:
When this command is used the install the that packages will be
listed under the optional Dependency section of the package.json file.
Optional dependencies are those packages which are only used when a
particular feature of the application is used and will not be required
if that functionality isn’t used.
1
npm install --save-optional
–no-save:
When this command is used with npm install it will not allow the
installed packages from being saved into the dependency section.
1
npm install --no-save
Note: NPM provides two additional options to save
dependencies into package.json file.
–save-exact or -E:
This is an additional or optional command provided by the npm that
will save the exact version of the installed packages which are
configured at the time of development. It will not download the
dependencies from npm’s default server range operator.
1
npm install --save-exact
–save-bundle or -B:
The following command is also an optional command when
1
--save-bundle
or
1
-B
is used. This will also add the saved dependencies under the
bundleDependency list.
Figure 1-1 shows a graphical overview of the assembly process. The
figure shows the preprocessor processing the assembly source (.asm) and
header (.h) files.
By default, the assembler processes an intermediate file to produce a
binary object file (.doj) and an optional listing file (.lst).
编写
Assembler directives are coded in assembly source files.
The directives allow you to define variables,
set up hardware features, and identify program
sections for placement within processor memory.
The assembler uses directives for guidance as it translates a
source program into object code.
注意:
Do not use a word processor that embeds
special control codes in the text.
Use an .asm extension to source file names to
identify them as assembly source files.
Data on the IIC-bus can be transferred at rates of up to 100 kbit/s
in the Standard-mode, up to 400 kbit/s in the Fast-mode, up to 1 Mbit/s
in Fast-mode Plus, or up to 3.4 Mbit/s in the High-speed mode.
Due to the variety of different technology devices (CMOS, NMOS,
bipolar) that can be connected to the IIC-bus, the levels of the logical
‘0’ (LOW) and ‘1’ (HIGH) are not fixed and depend on the associated
level of VDD . Input reference levels are set as 30 % and 70 % of VDD ;
VIL is 0.3VDD and VIH is 0.7V DD .
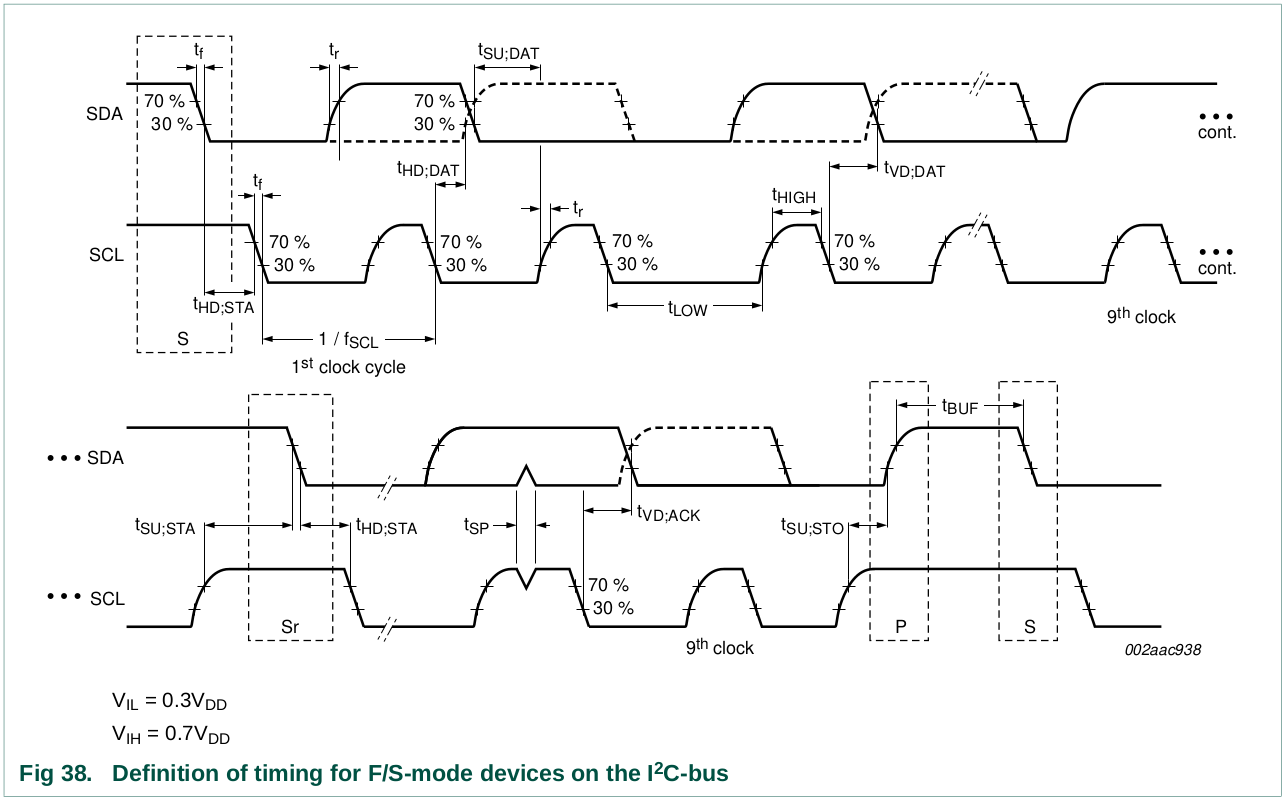
See Figure 38, timing diagram. Some legacy device input levels were
fixed at VIL = 1.5 V and VIH = 3.0 V, but all new
devices require this 30 %/70 % specification.
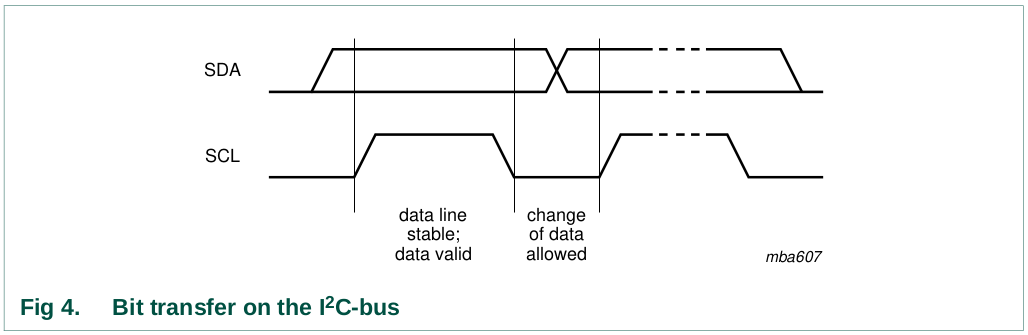
The data on the SDA line must be stable during the HIGH period of the
clock. The HIGH or LOW state of the data line can only change when the
clock signal on the SCL line is LOW (see Figure 4). One clock pulse is
generated for each data bit transferred.
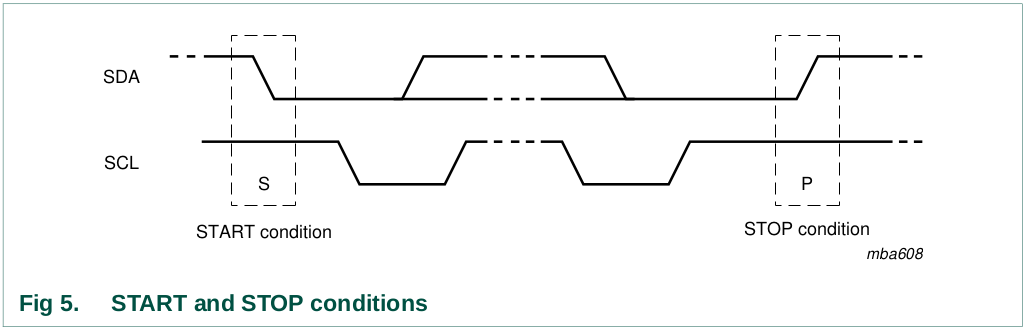
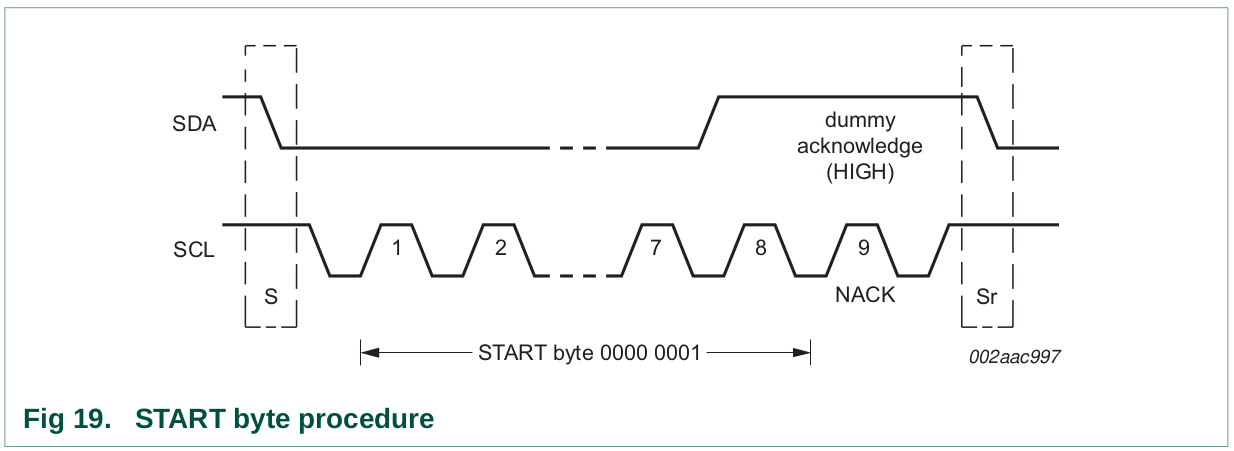
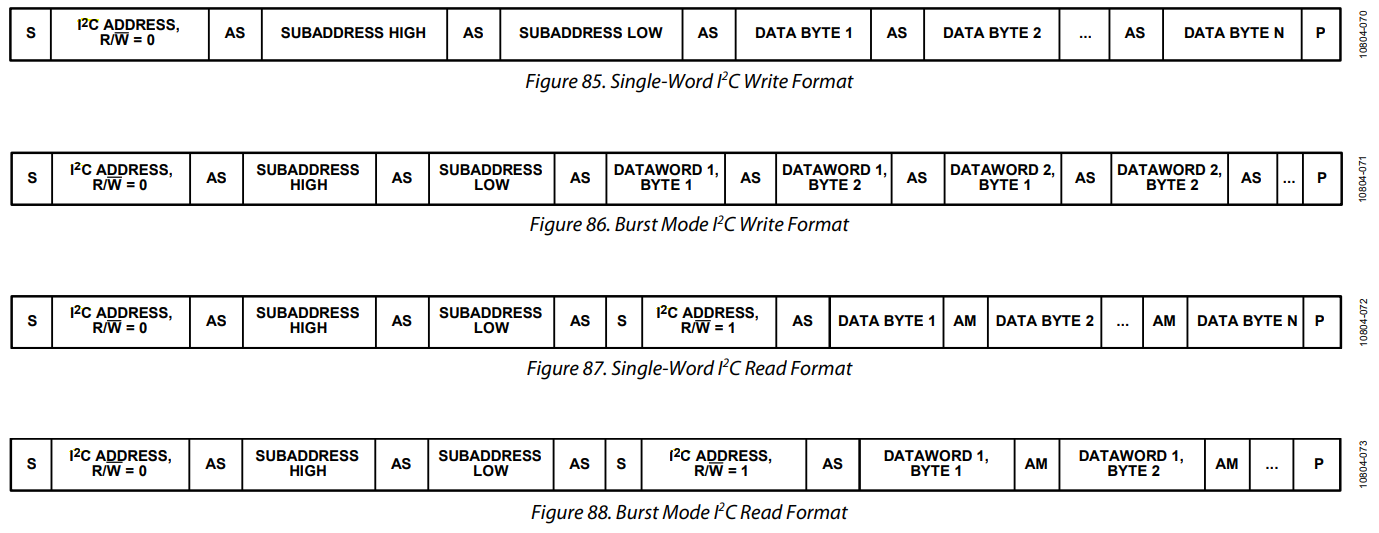
All transactions begin with a START (S) and are terminated by a STOP
(P) (see Figure 5). A HIGH to LOW transition on the SDA line while SCL
is HIGH defines a START condition. A LOW to HIGH transition on the SDA
line while SCL is HIGH defines a STOP condition.
The bus stays busy if a repeated START (Sr) is generated instead of a
STOP condition. In this respect, the START (S) and repeated START (Sr)
conditions are functionally identical. For the remainder of this
document, therefore, the S symbol is used as a generic term to represent
both the START and repeated START conditions, unless Sr is particularly
relevant.
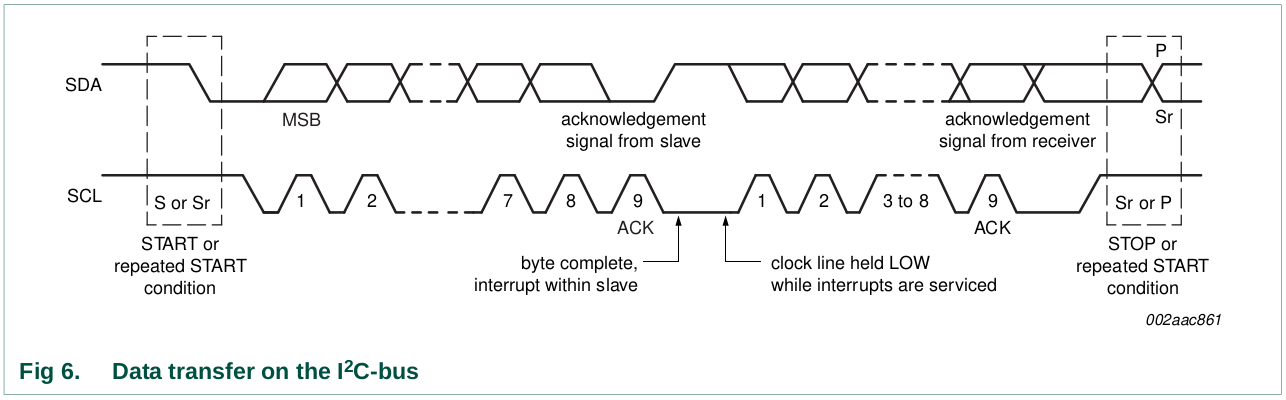
Every byte put on the SDA line must be eight bits long. The number of
bytes that can be transmitted per transfer is unrestricted. Each byte
must be followed by an Acknowledge bit.
Data is transferred with the Most Significant Bit (MSB)
first (see Figure 6). If a slave cannot receive or transmit
another complete byte of data until it has performed some other
function, for example servicing an internal interrupt, it can hold the
clock line SCL LOW to force the master into a wait state. Data transfer
then continues when the slave is ready for another byte of data and
releases clock line SCL.
The acknowledge takes place after every byte. The acknowledge bit
allows the receiver to signal the transmitter that the byte was
successfully received and another byte may be sent. The master generates
all clock pulses, including the acknowledge ninth clock pulse.
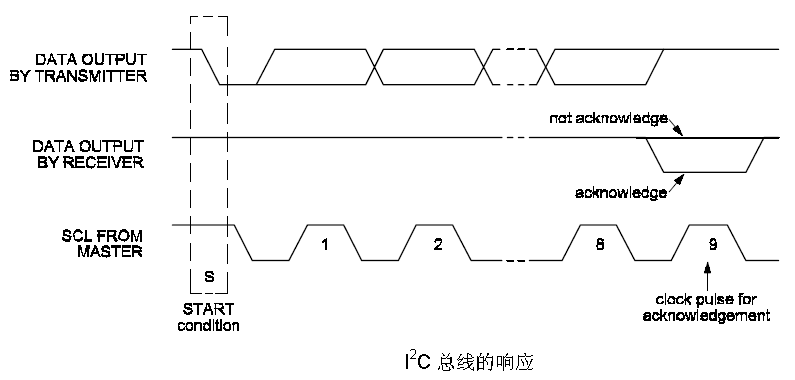
The Acknowledge signal is defined as follows: the transmitter
releases the SDA line during the acknowledge clock pulse so the
receiver can pull the SDA line LOW and it
remains stable LOW during the HIGH period of this clock pulse (see
Figure 4). Set-up and hold times (specified in Section 6) must also be
taken into account.
When SDA remains HIGH during this ninth clock pulse, this is defined
as the Not Acknowledge signal. The master can then generate either a
STOP condition to abort the transfer, or a repeated START condition to
start a new transfer.
以下为五种“未确认/未应答”的可能情况:There are five
conditions that lead to the generation of a NACK:
传输地址错误:No receiver is present on the bus
with the transmitted address so there is no device to respond with an
acknowledge.
实时处理中:The receiver is unable to receive or
transmit because it is performing some real-time function and is not
ready to start communication with the master.
数据/代码未定义:During the transfer, the receiver
gets data or commands that it does not understand.
正在传输中:During the transfer, the receiver
cannot receive any more data bytes.
未收到结束信号(收发身份未转换):A master-receiver
must signal the end of the transfer to the slave transmitter.
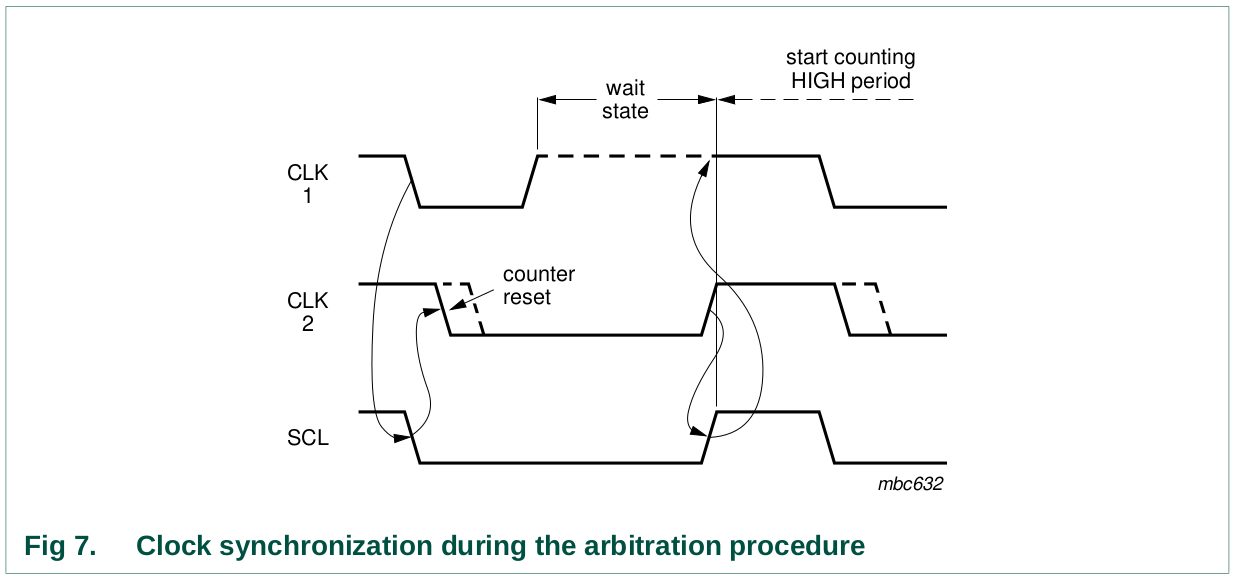
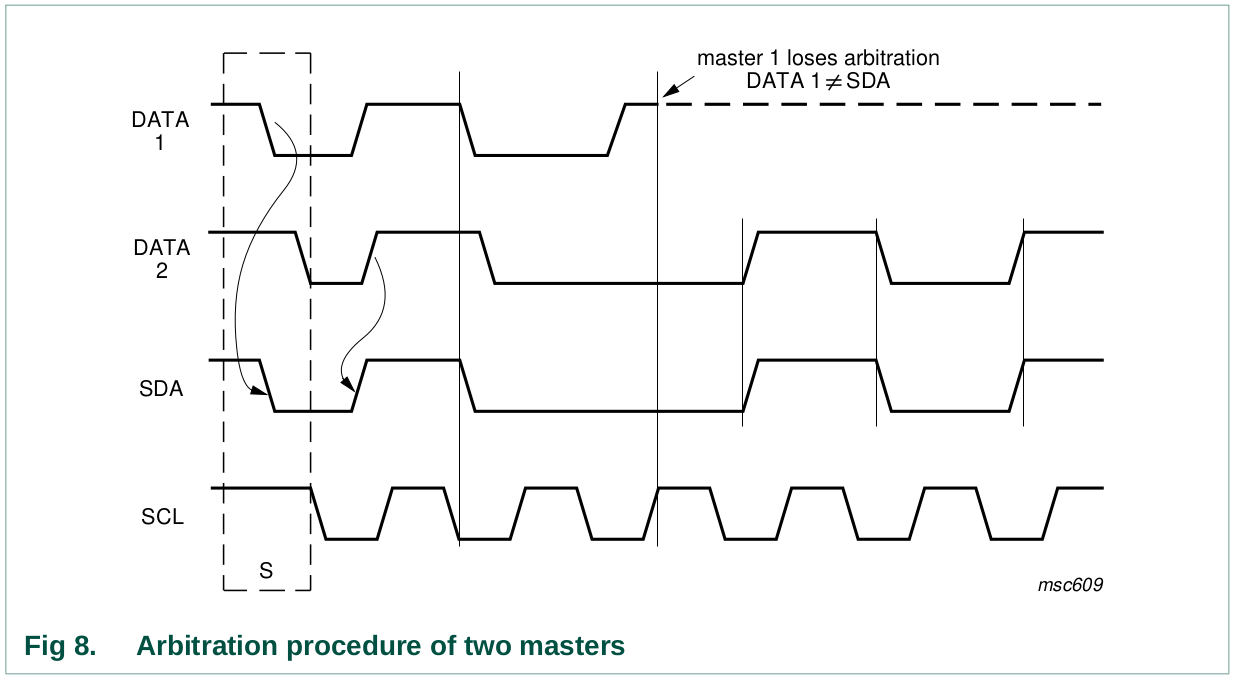
Clock synchronization is performed using the wired-AND connection of
IIC interfaces to the SCL line. This means that a HIGH to LOW transition
on the SCL line causes the masters concerned to start counting off their
LOW period and, once a master clock has gone LOW, it holds the SCL line
in that state until the clock HIGH state is reached (see Figure 7).
However, if another clock is still within its LOW period, the LOW to
HIGH transition of this clock may not change the state of the SCL line.
The SCL line is therefore held LOW by the master with the longest LOW
period. Masters with shorter LOW periods enter a HIGH wait-state during
this time.
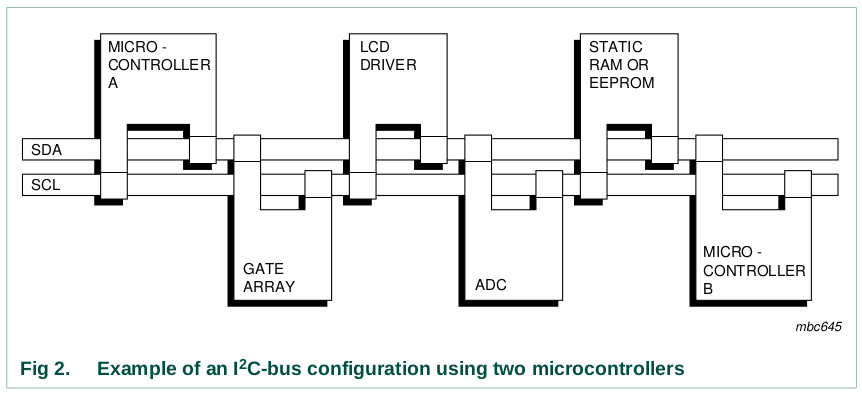
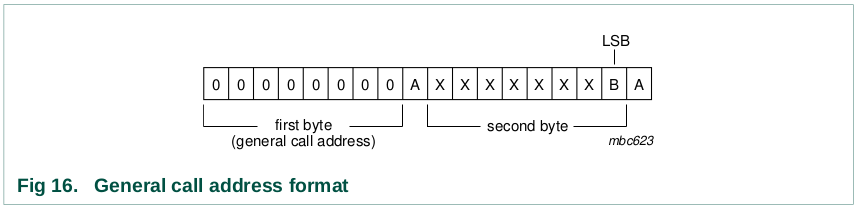
On receiving this 2-byte sequence, all devices designed to respond to
the general call address reset and take in the programmable part of
their address.
Q: what is the macro SIGMA_WRITE_DELAY supposed to
do? Is it a simple delay? Why are there parameters regarding the device
I2C address, data and length? A: This macro is used for
applications that need to pause the data writes for a specific purpose.
For example, if you need time for the PLL to be set before
starting to write to the rest of the registers. It could
be used as a simple delay, you’ll need to specify the device address
always because some applications can require more than one DSP; the
length is just the address byte length (could be 1 or 2 byte length) and
data is the value in hex that represents the total time in milliseconds
(that is up to the micro controller clock speed). The reason length is
used, is that some DSPs work with one and some other require two address
bytes.
<SigmaStudioFW.h> contains a lot of macros to be
defined. What I found by examinating all the code is that what macros
need to be defined depend on what you want to perform with your
microcontroller.
If you only need to load a DSP program with a call to
default_download(), well, you only need (at least for the ADAU1761)
to implement the two macros:
SIGMA_WRITE_REGISTER_BLOCK
SIGMA_WRITE_DELAY
The first one is the basis of all the loading of data into
program ram, parameter
ram, and registers. The second
one is only a delay (to be exact it serves to wait for the PLL to lock,
in any case most of the times it can be implemented as a
simple delay).
If you want to use sequences, that is to implement some control of
the DSP running with your microcontroller, you will probably need to
implement the other macros. In particular if you will control volume
sliders you will need to implement the conversion macros for integer or
float to the internal 5.23 representation. You can search elsewhere on
the forum, I saw some of this code.
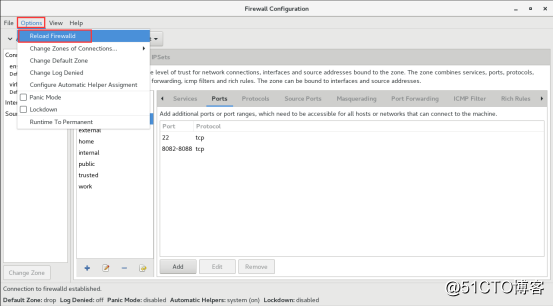
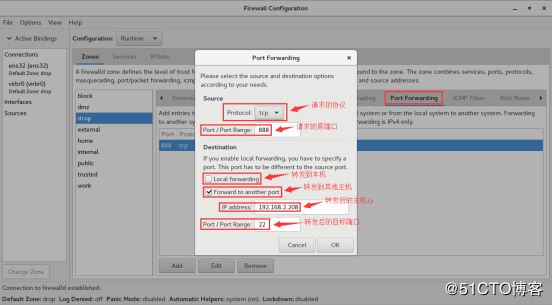
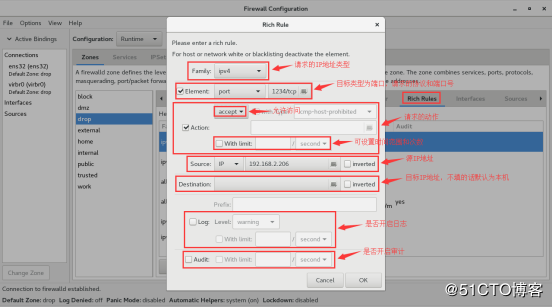
Firewalld provides a dynamically managed firewall with support for
network/firewall zones to define the trust level of network connections
or interfaces. It has support for IPv4, IPv6 firewall settings and for
ethernet bridges and has a separation of runtime and permanent
configuration options. It also supports an interface for
services or applications to add firewall rules directly.
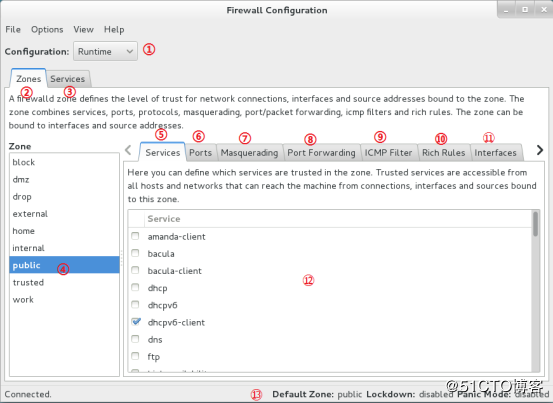
These are the zones provided by firewalld sorted according to the
default trust level of the zones from untrusted to
trusted:
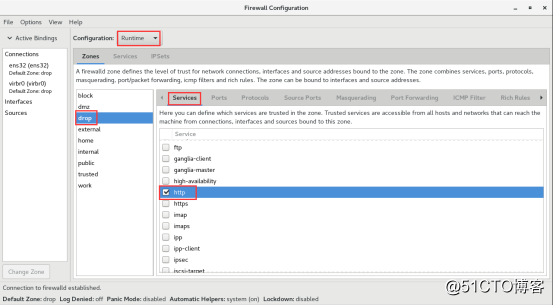
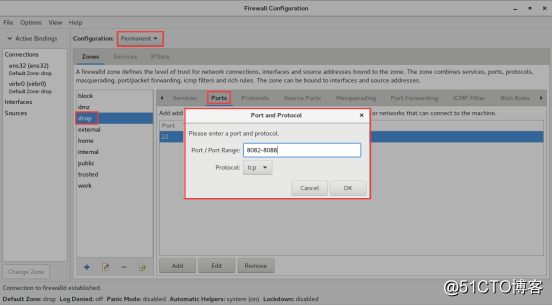
drop : Any incoming network packets are dropped,
there is no reply. Only outgoing network connections are possible.
block : Any incoming network connections are
rejected with an icmp-host-prohibited message for IPv4 and
icmp6-adm-prohibited for IPv6. Only network connections initiated within
this system are possible.
public : For use in public areas. You do not trust
the other computers on networks to not harm your computer. Only selected
incoming connections are accepted.
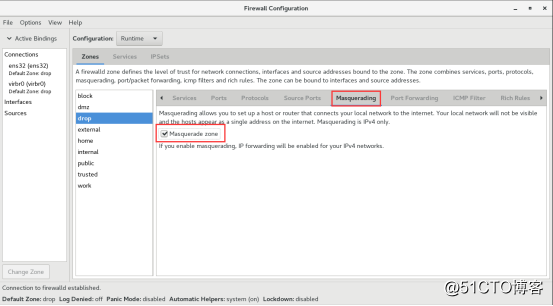
external : For use on external networks with
masquerading enabled especially for routers. You do not trust the other
computers on networks to not harm your computer. Only selected incoming
connections are accepted.
dmz : For computers in your demilitarized zone that
are publicly-accessible with limited access to your internal network.
Only selected incoming connections are accepted.
work : For use in work areas. You mostly trust the
other computers on networks to not harm your computer. Only selected
incoming connections are accepted.
home : For use in home areas. You mostly trust the
other computers on networks to not harm your computer. Only selected
incoming connections are accepted.
internal : For use on internal networks. You mostly
trust the other computers on the networks to not harm your computer.
Only selected incoming connections are accepted.
firewalld provides an init script for systems using classic SysVinit
and also a systemd service file. The following documentation is about
the systemd service used in Fedora, RHEL and CentOS distributions.
It is not recommended to use iptables directly while firewalld is
running as this could lead into some unexpected issues. If a user, for
example, is removing base rules or chains of the chain structure, then a
firewalld reload might be needed to create them again.
Install and enable firewalld
If the iptables, ip6tables, ebtables and ipset services are in
use:
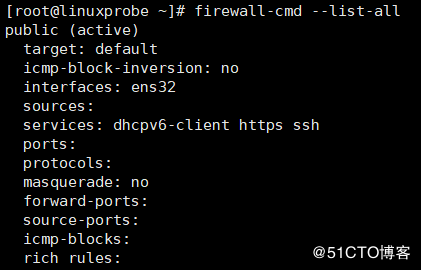
To check the firewall state you have different options. The fist
option is to use systemctl status firewalld the other one
is to use firewall-cmd --state.
The output of the systemctl command should look like this:
1 2 3 4 5 6 7 8 9
$ systemctl status firewalld ● firewalld.service - firewalld - dynamic firewall daemon Loaded: loaded (/usr/lib/systemd/system/firewalld.service; enabled; vendor pr Active: active (running) since Wed 2016-06-29 14:28:51 CEST; 1 weeks 6 days a Docs: man:firewalld(1) Main PID: 24540 (firewalld) Tasks: 2 (limit: 512) CGroup: /system.slice/firewalld.service └─24540 /usr/bin/python3 -Es /usr/sbin/firewalld --nofork --nopid
The output of the firewall-cmd command should look like this:
1 2
$ firewall-cmd --state running
Install
and enable iptables, ip6tables, ebtables and ipset services
If firewalld is enabled and you want to enable the iptables,
ip6tables, ebtables and ipset services instead:
The use of the mask line is recommended as systemd will start
firewalld if there is another service requires it or if the D-Bus
interface of firewalld is used. If the service only gets disabled, then
it will not be auto started anymore.
SQL 是 Structured Query Language 的缩写,规范的发音是
“ˌɛsˌkjuːˈɛl”。但是它的前身是著名的关系数据库原型系统 System R 所采用的
SEQUEL 语言,这也是为什么有很多人将其读作 “ˈsiːkwəl” 的来源。也有人类比
GNU 这个词的定义(GNU’s Not UNIX),认为 SQL 是 SQL Query Language
的缩写。