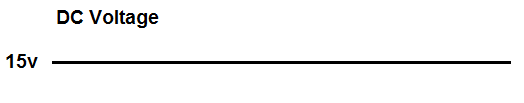In this tutorial, you will configure Visual Studio Code to use the
GCC C++ compiler (g++) and GDB debugger on Ubuntu in the Windows
Subsystem for Linux (WSL). GCC stands for GNU Compiler Collection;
GDB is the GNU debugger. WSL is a Linux environment within Windows that
runs directly on the machine hardware, not in a virtual machine.
Note: Much of this tutorial is applicable to working
with C++ and VS Code directly on a Linux machine.
Visual Studio Code has support for working directly in WSL with the
Remote
- WSL extension. We recommend this mode of WSL
development, where all your source code files, in addition to the
compiler, are hosted on the Linux distro. For more background, see VS Code
Remote Development.
After completing this tutorial, you will be ready to create and
configure your own C++ project, and to explore the VS Code documentation
for further information about its many features. This tutorial does not
teach you about GCC or Linux or the C++ language. For those subjects,
there are many good resources available on the Web.
Install Windows
Subsystem for Linux and then use the links on that same page to
install your Linux distribution of choice. This tutorial uses Ubuntu.
During installation, remember your Linux user password because you'll
need it to install additional software.
Open the Bash shell for WSL. If you installed an Ubuntu distro,
type "Ubuntu" in the Windows search box and then click on it in the
result list. For Debian, type "Debian", and so on.
Ubuntu in Start Menu
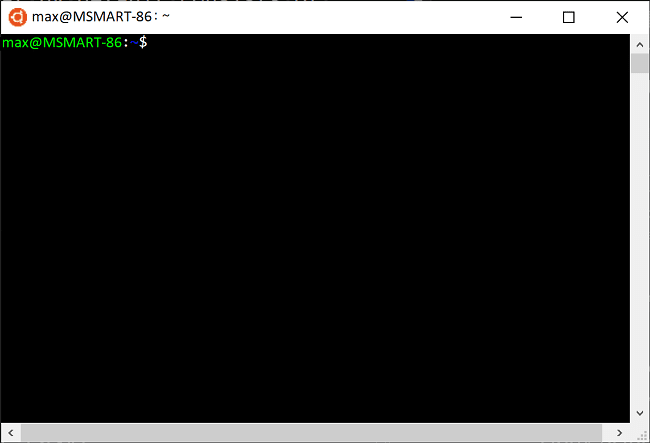
The shell appears with a command prompt that by default consists of
your user name and computer name, and puts you in your home directory.
For Ubuntu it looks like this:
Bash Shell
Make a directory called projects and then
subdirectory under that called helloworld:
1 2 3
mkdir projects cd projects mkdir helloworld
Although you will be using VS Code to edit your source code,
you'll be compiling the source code on Linux using the g++
compiler. You'll also debug on Linux using
GDB. These tools are not installed by default on Ubuntu, so you
have to install them. Fortunately, that task is quite easy!
From the WSL command prompt, first run
apt-get update to update the Ubuntu package lists. An
out-of-date distro can sometimes interfere with attempts to install new
packages.
1
sudo apt-get update
If you like, you can run
sudo apt-get update && sudo apt-get dist-upgrade to
also download the latest versions of the system packages, but this can
take significantly longer depending on your connection speed.
From the command prompt, install the GNU compiler tools and the
GDB debugger by typing:
1
sudo apt-get install build-essential gdb
image-20210419161354074
Verify that the install succeeded by locating g++ and gdb. If the
filenames are not returned from the whereis command, try
running the update command again.
1 2
whereis g++ whereis gdb
Note: The setup steps for installing the g++
compiler and GDB debugger apply if you are working directly on a Linux
machine rather than in WSL. Running VS Code in your helloworld project,
as well as the editing, building, and debugging steps are the same.
Navigate to your helloworld project folder and launch VS Code from
the WSL terminal with code .:
1 2
cd $HOME/projects/helloworld code .
You'll see a message about "Installing VS Code Server". VS
Code is downloading and installing a small server on the Linux side that
the desktop VS Code will then talk to.
image-20210419155740210
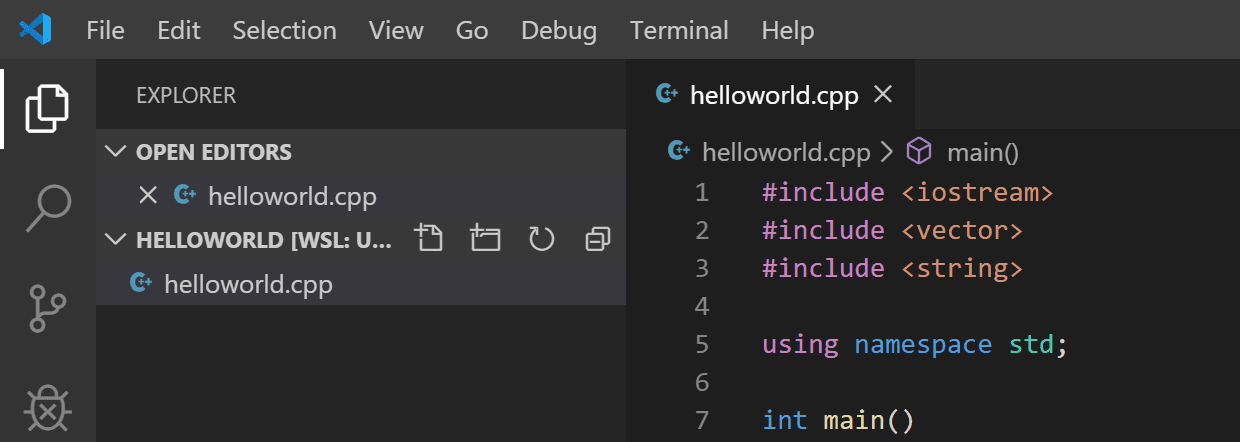
VS Code will then start and open the helloWorld folder.
The File Explorer shows that VS Code is now running in the context of
WSL with the title bar [WSL: Ubuntu].
File Explorer in WSL
You can also tell the remote context from the Status bar.
Remote context in the Status
bar
If you click on the Remote Status bar item, you will see a dropdown
of Remote commands appropriate for the session.
image-20210419155444952
For example, if you want to end your session running in WSL, you can
select the Close Remote Connection command from the
dropdown.
Running code . from your WSL command prompt
will restart VS Code running in WSL.
The code . command opened VS Code in the current
working folder, which becomes your "workspace". As you go through the
tutorial, you will see three files created in a .vscode
folder in the workspace:
c_cpp_properties.json (compiler path and IntelliSense
settings)
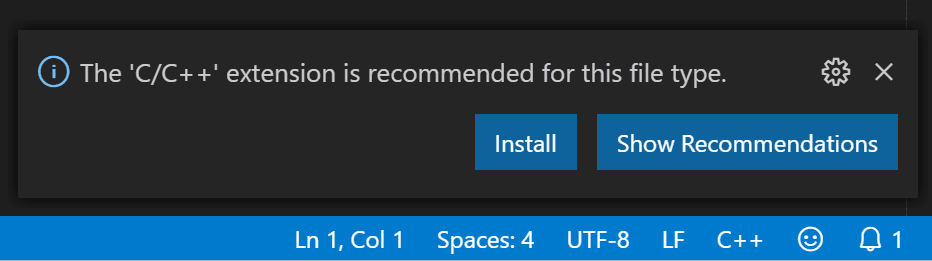
Once you create the file and VS Code detects it is a C++ language
file, you may be prompted to install the Microsoft
C/C++ extension if you don't already have it installed.
C++ extension notification
Choose Install and then Reload
Required when the button is displayed in the Extensions view to
complete installing the C/C++ extension.
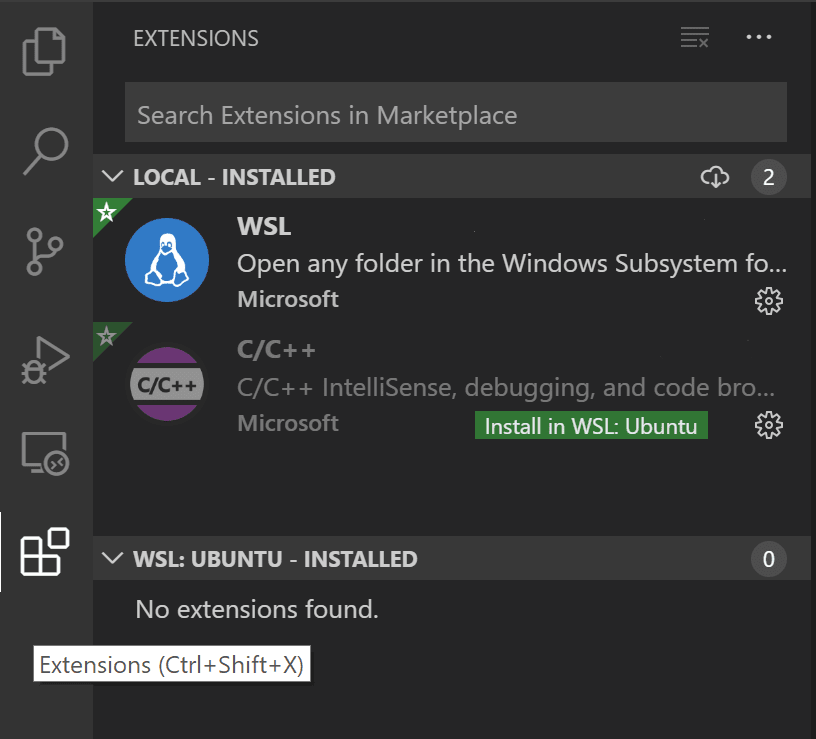
If you already have C/C++ language extensions installed locally in VS
Code, you'll need to go to the Extensions view (Ctrl+Shift+X) and
install those extensions into WSL. Locally installed extensions can be
installed into WSL by selecting the Install in WSL
button and then Reload Required.
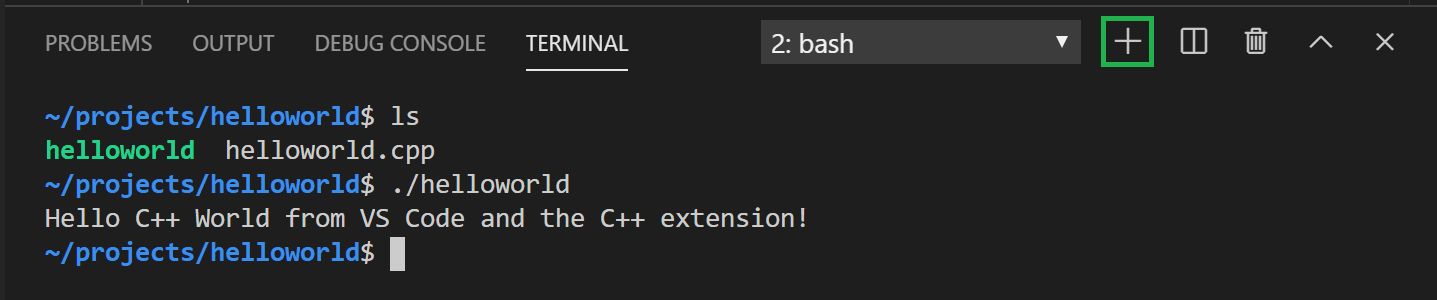
int main() { vector<string> msg {"Hello", "C++", "World", "from", "VS Code", "and the C++ extension!"};
for (const string& word : msg) { cout << word << " "; } cout << endl; }
Now press Ctrl+S to save the file. Notice how the file you just added
appears in the File Explorer view (Ctrl+Shift+E) in the
side bar of VS Code:
File Explorer
You can also enable Auto
Save to automatically save your file changes, by checking
Auto Save in the main File menu.
The Activity Bar on the far left lets you open different views such
as Search, Source Control, and
Run. You'll look at the Run view later
in this tutorial. You can find out more about the other views in the VS
Code User
Interface documentation.
In your new helloworld.cpp file, hover over
vector or string to see type information.
After the declaration of the msg variable, start typing
msg. as you would when calling a member function. You
should immediately see a completion list that shows all the member
functions, and a window that shows the type information for the
msg object:
Statement completion
IntelliSense
You can press the Tab key to insert the selected member; then, when
you add the opening parenthesis, you will see information about any
arguments that the function
requires.您可以按Tab键插入所选的成员;然后,当添加左括号时,您将看到关于函数所需的任何参数的信息。
Next, you will create a tasks.json file to tell VS Code
how to build (compile) the program. This task will invoke the g++
compiler on WSL to create an executable file based on the source
code.
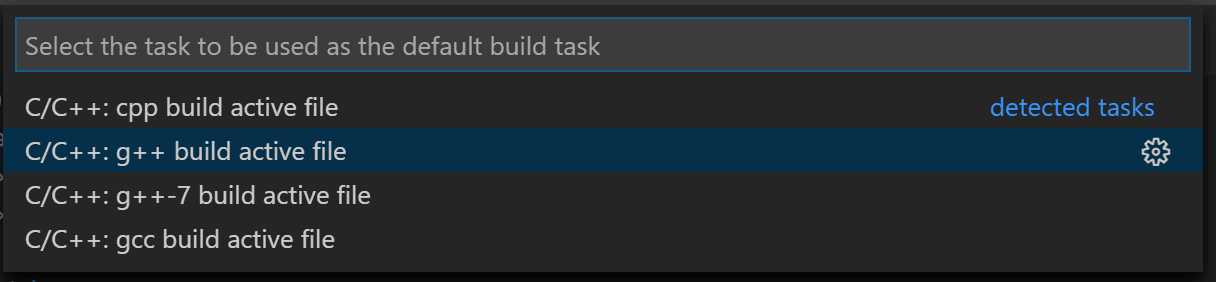
From the main menu, choose Terminal >
Configure Default Build Task. In the dropdown, which
will display a tasks dropdown listing various predefined build tasks for
C++ compilers. Choose g++ build active file, which will
build the file that is currently displayed (active) in the editor.
Tasks C++ build dropdown
This will create a tasks.json file in a
.vscode folder and open it in the editor.
Your new tasks.json file should look similar to the JSON
below:
The command setting specifies the program to run; in
this case that is g++. The args array specifies the
command-line arguments that will be passed to g++. These arguments must
be specified in the order expected by the compiler. This task tells g++
to take the active file (${file}), compile it, and create
an executable file in the current directory
(${fileDirname}) with the same name as the active file but
without an extension (${fileBasenameNoExtension}),
resulting in helloworld for our example.
Note: You can learn more about
tasks.json variables in the variables
reference.
The label value is what you will see in the tasks list;
you can name this whatever you like.
The "isDefault": true value in the group
object specifies that this task will be run when you press Ctrl+Shift+B.
This property is for convenience only; if you set it to false, you can
still run it from the Terminal menu with Tasks: Run Build
Task.
Go back to helloworld.cpp. Your task builds the
active file and you want to build helloworld.cpp.
To run the build task defined in tasks.json, press
Ctrl+Shift+B or from the Terminal main menu choose
Tasks: Run Build Task.
When the task starts, you should see the Integrated Terminal
panel appear below the source code editor. After the task completes, the
terminal shows output from the compiler that indicates whether the build
succeeded or failed. For a successful g++ build, the output looks
something like this:
G++ build output in terminal
Create a new terminal using the + button and
you'll have a bash terminal running in the context of WSL with the
helloworld folder as the working directory. Run
ls and you should now see the executable
helloworld (no file extension).
WSL bash terminal
You can run helloworld in the terminal by typing
./helloworld.
You can modify your tasks.json to build multiple C++
files by using an argument like "${workspaceFolder}/*.cpp"
instead of ${file}. You can also modify the output filename
by replacing "${fileDirname}/${fileBasenameNoExtension}"
with a hard-coded filename (for example 'helloworld.out').
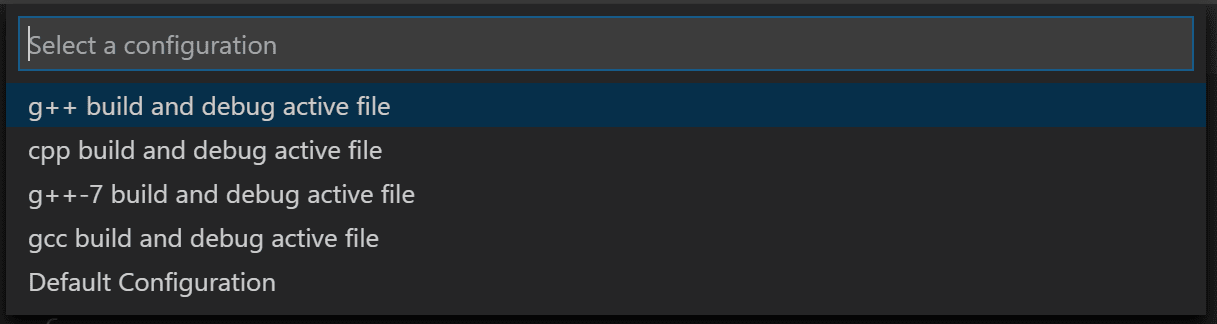
Next, you'll create a launch.json file to configure VS
Code to launch the GDB debugger when you press F5 to debug the program.
From the main menu, choose Run > Add
Configuration... and then choose C++
(GDB/LLDB).
You'll then see a dropdown for various predefined debugging
configurations. Choose g++ build and debug active
file.
C++ debug configuration
dropdown
VS Code creates a launch.json file, opens it in the
editor, and builds and runs 'helloworld'.
The program setting specifies the program you want to
debug. Here it is set to the active file folder
${fileDirname} and active filename without an extension
${fileBasenameNoExtension}, which if
helloworld.cpp is the active file will be
helloworld.
By default, the C++ extension won't add any breakpoints to your
source code and the stopAtEntry value is set to
false. Change the stopAtEntry value to
true to cause the debugger to stop on the main
method when you start debugging.
The remaining steps are provided as an optional exercise to help you
get familiar with the editing and debugging experience.
Go back to helloworld.cpp so that it is the active
file.
Press F5 or from the main menu choose Run > Start
Debugging. Before you start stepping through the code, let's
take a moment to notice several changes in the user interface:
The Integrated Terminal appears at the bottom of the source code
editor. In the Debug Output tab, you see output that
indicates the debugger is up and running.
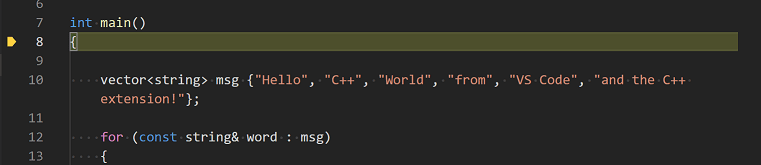
The editor highlights the first statement in the
main method. This is a breakpoint that the C++ extension
automatically sets for you:
Initial breakpoint
The Run view on the left shows debugging information. You'll see
an example later in the tutorial.
At the top of the code editor, a debugging control panel appears.
You can move this around the screen by grabbing the dots on the left
side.
Now you're ready to start stepping through the code.
Click or press the Step over icon in the
debugging control panel.
Step over button
This will advance program execution to the first line of the for
loop, and skip over all the internal function calls within the
vector and string classes that are invoked
when the msg variable is created and initialized. Notice
the change in the Variables window on the left.
Debugging windows
In this case, the errors are expected because, although the variable
names for the loop are now visible to the debugger, the statement has
not executed yet, so there is nothing to read at this point. The
contents of msg are visible, however, because that
statement has completed.
Press Step over again to advance to the next
statement in this program (skipping over all the internal code that is
executed to initialize the loop). Now, the Variables
window shows information about the loop variables.
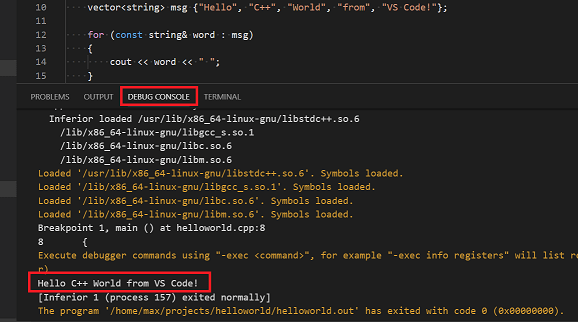
Press Step over again to execute the
cout statement. (Note that as of the March 2019 release,
the C++ extension does not print any output to the Debug
Console until the loop exits.)
If you like, you can keep pressing Step over
until all the words in the vector have been printed to the console. But
if you are curious, try pressing the Step Into button
to step through source code in the C++ standard library!
Breakpoint in gcc standard library
header
To return to your own code, one way is to keep pressing Step
over. Another way is to set a breakpoint in your code by
switching to the helloworld.cpp tab in the code editor,
putting the insertion point somewhere on the cout statement
inside the loop, and pressing F9. A red dot appears in the gutter on the
left to indicate that a breakpoint has been set on this line.
Breakpoint in main
Then press F5 to start execution from the current line in the
standard library header. Execution will break on cout. If
you like, you can press F9 again to toggle off the breakpoint.
When the loop has completed, you can see the output in the
Debug Console tab of the integrated terminal, along
with some other diagnostic information that is output by GDB.
Sometimes you might want to keep track of the value of a variable as
your program executes. You can do this by setting a
watch on the variable.
Place the insertion point inside the loop. In the
Watch window, click the plus sign and in the text box,
type word, which is the name of the loop variable. Now view
the Watch window as you step through the loop.
Watch window
Add another watch by adding this statement before the loop:
int i = 0;. Then, inside the loop, add this statement:
++i;. Now add a watch for i as you did in the
previous step.
To quickly view the value of any variable while execution is
paused on a breakpoint, you can hover over it with the mouse
pointer.
If you want more control over the C/C++ extension, you can create a
c_cpp_properties.json file, which will allow you to change
settings such as the path to the compiler, include paths, C++ standard
(default is C++17), and more.
You can view the C/C++ configuration UI by running the command
C/C++: Edit Configurations (UI) from the Command
Palette (Ctrl+Shift+P).
Command Palette
This opens the C/C++ Configurations page. When you
make changes here, VS Code writes them to a file called
c_cpp_properties.json in the .vscode
folder.
Command Palette
You only need to modify the Include path setting if
your program includes header files that are not in your workspace or in
the standard library path.
Visual Studio Code places these settings in
.vscode/c_cpp_properties.json. If you open that file
directly, it should look something like this:
When you are done working in WSL, you can close your remote session
with the Close Remote Connection command available in
the main File menu and the Command Palette
(Ctrl+Shift+P). This will restart VS Code running locally. You can
easily reopen your WSL session from the File >
Open Recent list by selecting folders with the
[WSL] suffix.
Create a new workspace, copy your .json files to it, adjust the
necessary settings for the new workspace path, program name, and so on,
and start coding!
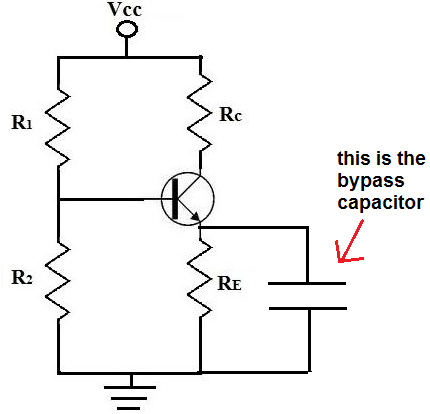
A bypass capacitor is a capacitor that shorts AC signals to ground,
so that any AC noise that may be present on a DC signal is removed,
producing a much cleaner and pure DC signal.
A bypass capacitor essentially bypasses AC noise that may be on a DC
signal, filtering out the AC, so that a clean, pure DC signal goes
through without any AC ripple.
For example, you may want a pure DC signal from a power source.
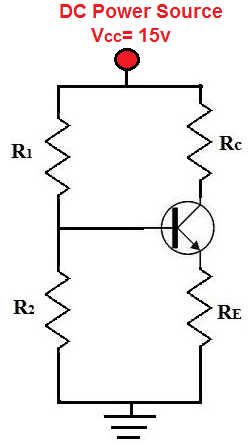
Below is a transistor circuit. A transistor is an active device, so
in order to work, it needs DC power. This power source is VCC. In this
case, VCC equals 15 volts.
DC Power Source for
Transistor
This 15 volts provides power to the transistor so that the transistor
can amplify signals. We want this signal to be as purely DC as possible.
Although we obtain our DC voltage, VCC, from a DC power source such as a
power supply, the voltage isn't always purely DC. In fact, many times
the voltage is very noisy and contains a lot of AC ripple on it,
especially at the 60Hz frequency because this is the frequency at which
AC signals run in many countries.
So although we want a pure DC signal, such as below:
Pure DC Voltage
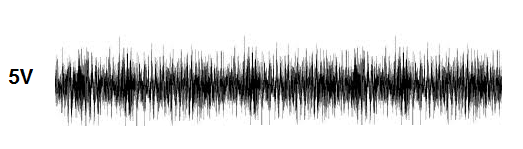
Many times, we get a noisy signal that looks like:
Noisy DC Voltage Signal
A DC signal such as this is actually very common. This is undesired
because it adds noise to the transistor circuit. Therefore, this noisy
DC signal will be imposed on the AC signal. So the AC signal which may
have music or some type of recording will now have much more noise.
This noise which is on the signal is AC ripple. Many times when using
a DC power supply connected to an AC power outlet, it will have some of
the AC noise transfer to the DC power voltage. AC ripple can also appear
from other sources, so even batteries can produce noise.
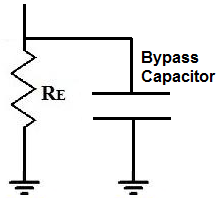
To eliminate this AC ripple, we use a bypass capacitor. So our
transistor circuit above will have a bypass capacitor added to it:
Bypass Capacitor for a Transistor
Circuit
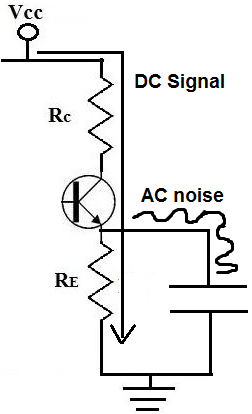
A capacitor is a device that offers a tremendously high resistance
for signals of low frequencies. Therefore, signals at low frequencies
will not go through them. This is because signals (current) always takes
the path of least resistance. Therefore, they will instead go through
the resistor, RE. Remember, again, this is for low frequency signals,
which is basically DC signals.
However, capacitors offer much less resistance at higher frequencies
(AC signals). So AC signals will go through the capacitor and then to
gorund. Therefore, DC signals will go through the resistor, RE, while AC
signals will go through the capacitor, getting shunted to ground. So AC
signals get shunted to ground. This is how we have a clean DC signal
across our circuit, while AC noise imposed on it is bypassed to
ground.
How a Bypass Capacitor Works
So a bypass capacitor blocks the DC from entering it by the great
resistance it offers to the signal but accepts the AC noise that may be
on the DC line and shunts or bypasses it to ground. This is how bypass
capacitors work.
How to Choose
the Value of the Bypass Capacitor
Now that you know conceptually what a bypass capacitor is, the next
step is to know how to select the value of the bypass capacitor.
And selecting the value is pretty straightforward.
The value of the bypass capacitor should be at least 1/10th of the
resistance across the emitter resistance, RE at the lowest frequency
intended to be bypassed.
Because capacitors are reactive devices, they have different
resistances to signals based on the signal's frequency. This is referred
to as the capacitor's reactance, which can be seen as the resistance it
offers. We want the capacitor to have 1/10th of the resistance to the
flow of current than what the resistor offers for the frequency signal
that we want to bypass.
If you visualize the current moving through the transistor, it can
take one of 2 paths once it passes the collector and moves through the
emitter. Current can either go the resistor, RE or current can flow
through the bypass capacitor. Current always takes the path of least
resistance. Therefore, current will take the path of the lower
resistance. This is why you want the value of the resistance of the
bypass capacitor to be at least 1/10th the value of the emitter resistor
or, even better, less than one-tenth. We want the AC current to flow
through the least resistance path, which is the bypass capacitor if the
correct value is chosen.
However, DC signals do not see it as AC. To DC, the capacitor has
infinite resistance. So DC will automatically go through the RE
resistor, which offers lower resistance by far to the infinite
resistance of the capacitor.
AC, however, does not see infinite resistance for the capacitor. If
we choose the value correctly for the capacitor, we can make the
capacitor a much lower-resistance path to ground, thus shorting out the
AC signal to ground.
So let's go over a practical example of how we would select the
bypass capacitor value.
Let's say we want to bypass the lowest possible frequency of 50Hz,
because the frequency of AC voltages worldwide are 50-60Hz. Therefore,
this frequency can be a very problematic because often there is AC
ripple at this frequency.
Remember, when we said we bias the value of the bypass capacitor
based on the lowest frequency that we want to bypass. So by selecting
the frequency of 50Hz, this blocks frequencies from 50Hz and higher; so
it covers 60Hz. As frequency of an AC signal increases, the resistance
of the capacitor decreases and decreases with each increase. Therefore,
all the frequencies above the frequency value that we choose get
bypassed easier and easier. We'll demonstrate this all
mathematically.
So we decided we want to bypass AC signals 50Hz or higher to
ground.
The typical value of an emitter resistor is 400-500Ω. The resistance
is kept low so that gain on the transistor isn't lowered too much.
So let's say we choose an emitter resistor of 470Ω.
This means that we want the reactance of the capacitor to be
one-tenth of 470Ω or less, which is 47Ω or lower. So this is our
target.
The formula for the reactance of a capacitor is, XC= 1/2πfc=
1/2(3.14)(50Hz)(C)=47Ω. Solving for the capacitance, C, we get the value
of approximately 67μF. So we need a capacitor of at least 67μF to get a
resistance of one-tenth the value of 470Ω resistor.
Since a 67μF capacitor isn't readily available, we can round up to
100μF, which is readily available and easy to obtain. This is even
better, because with a larger capacitance, the capacitor offers even
less resistance to the AC signal. If we plug a 100μF capacitor into the
same capacitor reactance formula, we get XC= 1/2πfc=
1/2(3.14)(50Hz)(100μF)=31.8Ω. This is much lower than 1/10 of the 470Ω
resistor that we have in parallel. So it will act effectively to short
all AC signals 50Hz or higher to ground to clean up the DC signal.
Even if you wanted, you could increase the capacitance even more to
allow for less AC noise on the signal. But a lot of times, this will not
be done for cost and size constraints reasons. The larger the size a
capacitor is, the more it costs per unit. Also the larger the size of a
capacitor, the larger physically is. Therefore, if a company is
designing a product, the size of the capacitor could be a problem if
there are size constraint issues. The way things are going in
electronics, companies want products to be as small and concise as
possible. So due to reasons such as these, larger value capacitors won't
always be chosen, but theoretically, they would increase the purity of
the DC signal, by allowing more AC to ground.
So again, this is a summary of what a bypass capacitor is and how to
select the value of them based on the lowest AC signal desired to be
filtered out and the value of the resistance in parallel with the
capacitor.
You can check out our bypass
capacitor calculator to calculate the value of a bypass capacitor
based on the input AC signal frequency and the value of the resistor in
parallel.
SSH is a program for logging into a remote machine and for excuting
commands on a remote machine.
It's intended to provide secure encrypted communications between two
untrusted hosts over and insecure network.
X11 connections, arbitrary TCP ports and UNIX-domain sockets can also
be forwarded over the secure channel.
Authentication
The OpenSSH SSH client supports SSH protocol 2.
Five available authentication methods: GSSAPI-based / host-based /
public key / challenge-response and password.
Host-based
If the machine the user logs in from is listed in
/etc/hosts.equiv or /etc/ssh/shosts.equiv on
the remote machine, the user is non-root and the user names are the same
on both sides, or if the files ~/.rhosts or
~/.shosts exist in the user's home directory on the remote
machine and contain a line containing the name of the client machine and
the name of the user on that machine, the user is considered for login.
Additionally, the server must be able to verify the client's host key
(see the description of /etc/ssh/ssh_known_hosts and
~/.ssh/known_hosts, below) for login to be permitted. This
authentication method closes security holes due to IP spoofing, DNS
spoofing, and routing spoofing.
[Note to the administrator:
/etc/hosts.equiv, ~/.rhosts, and the
rlogin/rsh protocol in general, are inherently insecure and should be
disabled if security is desired.]
Public key
The scheme is based on public-key cryptography, using cryptosystems
where encryption and decryption are done using separate keys, and it is
unfeasible to derive the decryption key from the encryption key. The
idea is that each user creates a public/private key pair for
authentication purposes.
The server knows the public key, and only the user knows
the private key. ssh implements public key authentication
protocol automatically, using one of the DSA,
ECDSA, Ed25519 or RSA
algorithms. The HISTORY section of ssl(8) [i]
on non-OpenBSD systems contains a brief discussion of the DSA and RSA
algorithms.
The file ~/.ssh/authorized_keys lists the public keys
that are permitted for logging in. When the user logs in, the ssh
program tells the server which key pair it would like to use for
authentication. The client proves that it has access to the private key
and the server checks that the corresponding public key is authorized to
accept the account.
The user should then copy the public key to
~/.ssh/authorized_keys in his/her home directory on the
remote machine. The authorized_keys file corresponds to the
conventional ~/.rhosts file, and has one key per line,
though the lines can be very long. After this, the user can log in
without giving the password.
ssh-keygen
To generate a public key for ssh, we need to use:
1
ssh-kegen -t rsa
The terminal will ask if /root/.ssh/id_rsa the file you
save the key:
1 2
Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa):
The terminal will require you to enter the passphrase
twice.
1 2
Enter passphrase (empty for no passphrase): Enter same passphrase again:
Identification is the private key used by
the server(the remote machine). And the public
key is generated for the client to authenticate while
logging in the server.
1 2 3 4 5
Your identification has been saved in /root/.ssh/id_rsa Your public key has been saved in /root/.ssh/id_rsa.pub The key fingerprint is: SHA256: ******* The key's randomart imge is:
The user creates his/her key pair by running ssh-keygen(1).
This stores the private key in
~/.ssh/id_dsa (DSA), ~/.ssh/id_ecdsa (ECDSA),
~/.ssh/id_ecdsa_sk (authenticator-hosted ECDSA),
~/.ssh/id_ed25519 (Ed25519),
~/.ssh/id_ed25519_sk (authenticator-hosted Ed25519), or
~/.ssh/id_rsa (RSA) .
The the public key stores in
~/.ssh/id_dsa.pub (DSA), ~/.ssh/id_ecdsa.pub
(ECDSA), ~/.ssh/id_ecdsa_sk.pub (authenticator-hosted
ECDSA), ~/.ssh/id_ed25519.pub (Ed25519),
~/.ssh/id_ed25519_sk.pub (authenticator-hosted Ed25519), or
~/.ssh/id_rsa.pub (RSA) in the user's home
directory.
Check and copy your .pub file to the local computer.
1 2
cd ~/.ssh/ vim id_rsa.pub
Permissions 0644
1
chmod 0600 ~/.ssh/id_rsa
Login Format
user@hostname : root@qq.com
ssh://root@hostname:port :
ssh://root@qq.com:666
SSL
基于 SSL 证书,可将站点由 HTTP(Hypertext Transfer Protocol)切换到
HTTPS(Hyper Text Transfer Protocol over Secure Socket
Layer),即基于安全套接字层(SSL)进行安全数据传输的加密版 HTTP
协议。
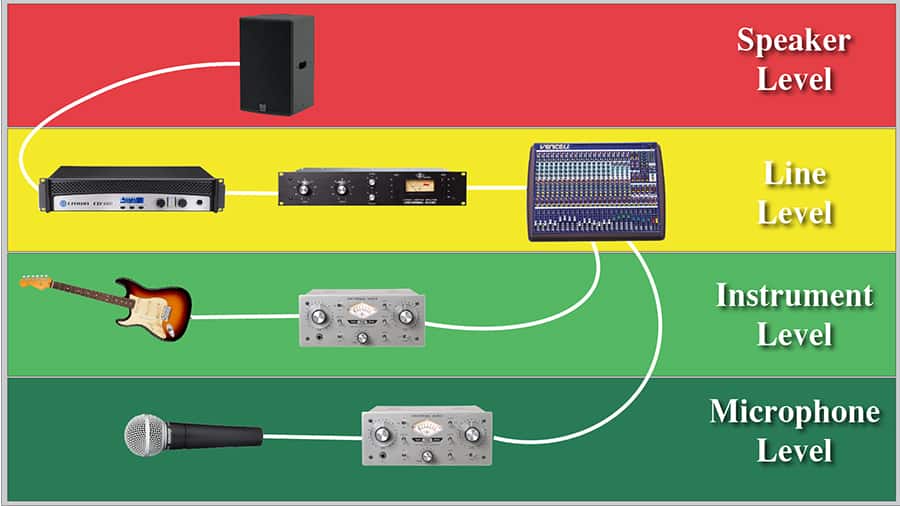
In this post, you’ll learn the difference between microphone level
and line level, as well as other levels commonly used in professional
audio such as instrument level and speaker level.
What is the difference between microphone level and line level?
Microphones and instruments output very low signal voltages,
while +4dBu is the line level is the standard voltage level for
professional audio equipment.
In pro audio, you’ll generally be dealing with four types of
audio signals: Mic Level, Instrument Level, Line Level, and Speaker
Level
Microphone Level
A microphone captures sound by converting pressure changes in the air
into electrical currents in a wire. The electrical currents created by
these pressure changes are very subtle. That’s why we use a microphone
preamp – to amplify the signal to a more usable level.
A microphone preamp takes in a mic level signal, amplifies it, and
outputs a line level signal. This is controlled by the gain knob on your
mixing console, audio interface, or outboard mic pre.
Instrument Level
The pickups of an electric guitar convert the vibrations of the
strings into electrical currents. Similar to those from a microphone,
the electrical currents from a guitar pickup are very weak.
A preamp can also be used to boost instrument level signals to line
level.
Once an input signal is brought up to line level, it is optimized for
use with professional audio equipment, such as mixing consoles, outboard
effects, and amplifiers.
Professional vs Consumer
Line Level
There are two standards for line level: +4 dBu (professional) and -10
dBV (consumer).
Watch this video to learn the difference between professional and
consumer line level. I also wrote a post on professional
vs consumer audio levels that will help you understand the
difference.
Speaker Level
Line level is adequate for sending signals between devices, but not
strong enough to power a speaker.In order to power a speaker, the line
level signal needs to be amplified again.
This can be done with a power amplifier. A power amp takes in a line
level signal, amplifies it, and outputs a speaker level signal that is
strong enough to power a speaker.
A Complete Audio System
In a complete system, you might run a microphone through a preamp and
an electric guitar through another preamp.
Once those signals are at line level, you can send them through
outboard effects and eventually to an amplifier, which will add enough
gain to the signal to power a speaker.
functionHelloWrold(){ //To use keyword `function` instead of `class` to define a class this.printInfo = function(){ return"Hi! JavaScript!\n"; } } var oHelloWorld = new HelloWorld(); // Make a new object of the class named `HelloWorld` var result = oHelloWorld.printInfo(); //Call the method of the object to assign document.write(result);
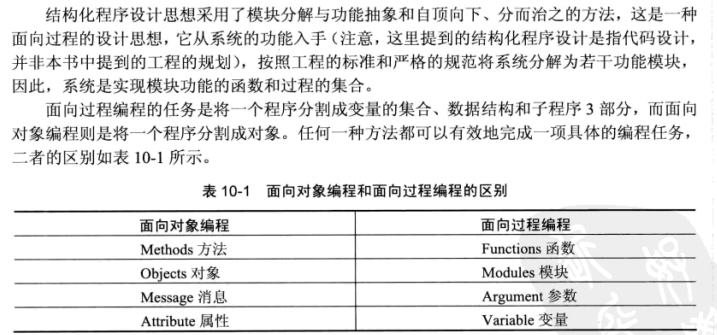
如果只需要在作用域内维持变量的生命周期,最好就用自动变量,这样是最简单方便高效的。其他情况可考虑用自由存储、静态局部/全局变量,或类的(静态)成员变量。它们各有不同特点,不在此答案详述。另外,由于
C++
不支持可变长数组(VLA),不可以定义动态长度的自动变量(成员变量也不行),这个情况下也需要用
new[] 来创建动态长度的数组。
自动变量会在作用域(如函数作用域、块作用域等)结束后析构、释放内存。因为分配和释放的次序是刚好完全相反的,所以可用到堆栈先进后出(first-in-last-out,
FILO)的特性,而 C++ 语言的实现一般也会使用到调用堆栈(call
stack)来分配自动变量(但非标准的要求)。
自由存储可以在函数结束后继续生存,所以也需要配合 delete
来手动析构、释放内存(也可使用智能指针避免手动
delete)。由于分配和释放次序没有限制,不能使用堆栈这种数据结构做分配,实现上可能采用自由链表(free
list)或其他动态内存分配机制。
An application that uses IPC APIs—such as MessageQ,
GateMP, and ListMP—must include the
Ipc module header file and call Ipc_start() in the
main() function. Ipc_start() does
the following:
初始化:Initializes a number of objects and modules used by
IPC.
同步:Synchronizes multiple processors so they can boot in any
order.
NOTES: If the main() function calls any
IPC APIs, the call to Ipc_start() must be placed before any
calls to IPC modules.
调用顺序
Firstly, initialize a MODULE_Params structure to its
default values via a MODULE_Params_init() function. The
creator thread can then set individual parameter fields in this
structure as needed.
Secondly, calls the MODULE_create() function to creates
the instance and initializes any shared memory used by the instance.
If the instance is to be opened remotely, a unique name must be
supplied in the parameters.
Other threads can access this instance via the
MODULE_open() function, which returns a handle with
access to the instance. The name that was used for instance
creation must be used in the MODULE_open() function.
Finally, the thread that called MODULE_create() can
call MODULE_delete() to free the memory used by the
instance.
All threads that opened an instance must close that instance
before the thread that created it can delete it.Also, a thread
that calls MODULE_create() cannot call
MODULE_close().Likewise, a thread that calls
MODULE_open() cannot call
MODULE_delete().
#include<ti/ipc/Ipc.h> ... Int main(Int argc, Char* argv[]) { Int status; /* Call Ipc_start() */ status = Ipc_start(); if (status < 0) { System_abort("Ipc_start failed\n"); } BIOS_start(); return (0); }
MessageQ_Create() 使用示例
1 2 3 4
messageQ = MessageQ_create(DSP_MESSAGEQNAME, NULL); if (messageQ == NULL) { //an error occurred when creating the object System_abort("MessageQ_create failed\n"); }
Error Handling in IPC
Success codes always have values greater or equal to zero. The
Failure codes are always negative.
1 2 3 4 5 6 7 8
MessageQ_Msg msg; MessageQ_Handle messageQ; Int status; ... status = MessageQ_get(messageQ, &msg, MessageQ_FOREVER); if (status < 0) { System_abort("Should not happen\n"); }
IPC Module Configuration
Configure how the IPC module synchronizes processors by configuring
the Ipc.procSync property. For example:
1 2 3
/* CONFIGURATION ABOUT INTER-PROCESS COMMUNICATION */ var Ipc = xdc.useModule('ti.sdo.ipc.Ipc'); Ipc.procSync = Ipc.ProcSync_ALL;
Here are three options: Ipc.ProcSync_ALL |
Ipc.ProcSync_PAIR | Ipc.ProcSync_NONE
Options
Conditions
Specialties
Ipc.ProcSync_ALL
- IPC processors on a device start up at the same time -
Connections should be established between every possible pair of
processors
- Ipc_start() API automatically attaches to and
synchronizes all remote processors. - Application
should never callIpc_attach().
Ipc.ProcSync_PAIR(Default Mode)
One of the following is true: - You need to control when
synchronization with each remote processor occurs. - Useful work can
be done while trying to synchronize with a remote processor by yielding
a thread after each attempt to Ipc_attach() to the processor. -
Connections to some remote processors are unnecessary and should be made
selectively to save memory.
- Must explicitly call Ipc_attach() to attach to a
specific remote processor. - Ipc_start() performs
system-wide IPC initialization, but does not make connections to
remote processors.
Ipc.ProcSync_NONE
Use this option with caution. It is intended for use
in cases where the application performs its own synchronization and you
want to avoid a potential deadlock situation with the IPC
synchronization.
Ipc_start() doesn’t synchronize any processors before
setting up the objects needed by other modules.
Attach and Detach
(依附与分离)
In addition to the default actions performed when attaching to or
detaching from a remote processor, You can configure a function to
perform custom actions.
Attach and Detach are provided for the processor synchronization:
Ipc_attach() Creates a connection to the specified
remote processor.
Ipc_detach() Deletes the connection to the specified
remote processor.
在 .cfg
文件中以下为两个互相依赖和两个互相分离的函数配置,每一组函数都会传递一个不同的参数:
1 2 3 4 5 6 7 8 9 10
var Ipc = xdc.useModule('ti.sdo.ipc.Ipc');
var fxn = new Ipc.UserFxn; fxn.attach = '&userAttachFxn1'; fxn.detach = '&userDetachFxn1'; Ipc.addUserFxn(fxn, 0x1);
These functions run near the end of
Ipc_attach() and near the beginning of
Ipc_detach() , respectively.
Such functions must be non-blocking and must run to
completion.
这些被定义的函数必须为非阻塞且(一旦开始就)运行到底。
注意: Call Ipc_attach() to the
processor that owns shared memory region 0 (usually the processor with
id = 0) before making a connection to any other remote processor. For
example, if there are three processors configured with
MultiProc, #1 should attach to #0 before it
can attach to #2.
NMI,即 不可屏蔽中断(Non Maskable
Interrupt)。NMIG,即
不可屏蔽中断产生寄存器(NMI Generation Register
(NMIGRx))。NMIGRx registers are used for generating NMI events
to the corresponding CorePac. The C6657 has two NMIGRx registers (NMIGR0
and NMIGR1). The NMIGR0 register generates an NMI event to CorePac0, and
the NMIGR1 register generates an NMI event to CorePac1.Writing 1 to the
NMIG field generates an NMI pulse. Writing 0 has no effect and reads
return 0 and have no other effect.
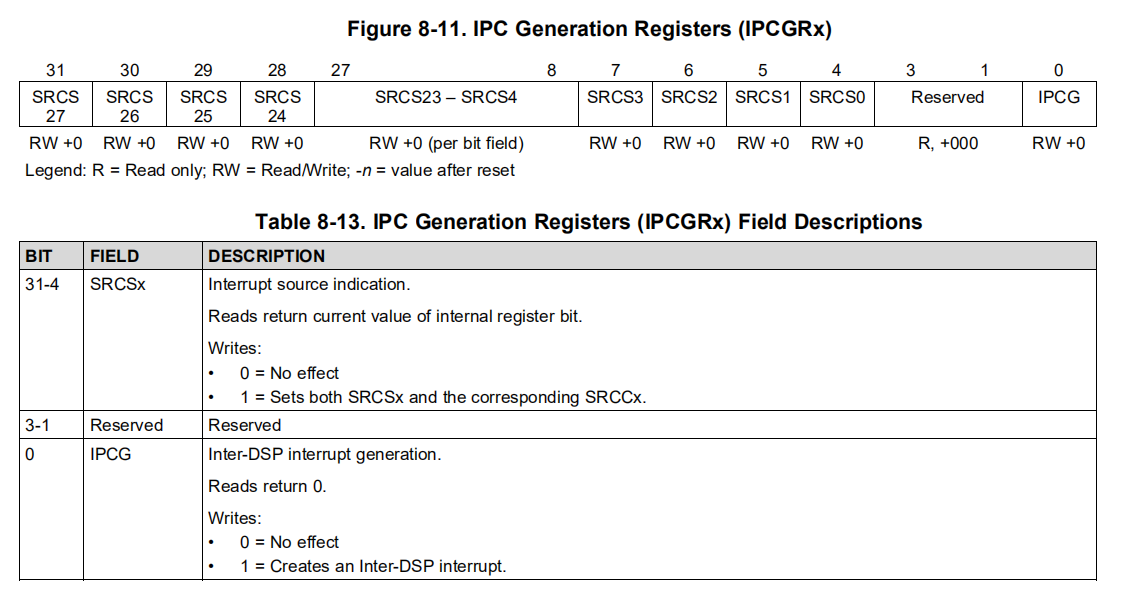
IPCGRx,即
进程间通信产生寄存器(IPC interrupt generation
register)。IPCGRx are to facilitate inter CorePac interrupts. The C6657
has two IPCGRx registers (IPCGR0 and IPCGR1). These registers can be
used by external hosts or CorePacs to generate interrupts to other
CorePacs. A write of 1to the IPCG field of the IPCGRx register will
generate an interrupt pulse to CorePacx (0 <= x <= 1).
IPCARx,即 IPC中断确认寄存器(IPC
interrupt-acknowledgement registers)。IPCARx are to facilitate
inter-CorePac core interrupts. The C6657 has two IPCARx registers
(IPCAR0 and IPCAR1). These registers also provide a Source ID
facility by which up to 28 different sources of interrupts can be
identified. Allocation of source bits to source processor and meaning is
entirely based on software convention. The register field descriptions
are shown in the following tables. Virtually anything can be a source
for these registers as this is completely controlled by software. Any
master that has access to BOOTCFG module space can write to these
registers.
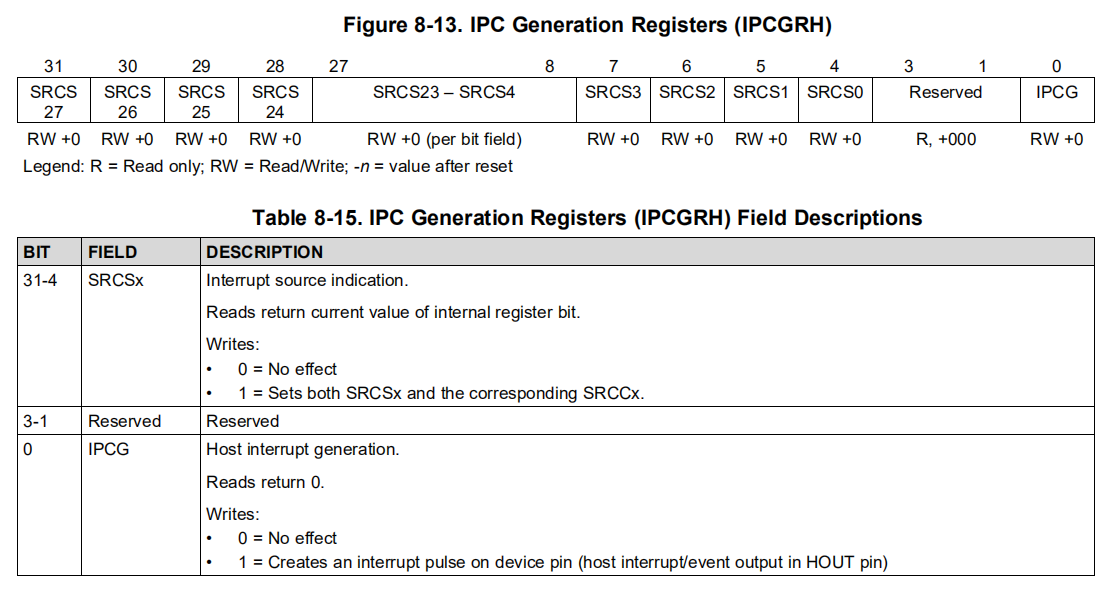
IPCGRH,即 主机IPC产生寄存器(IPC
Generation Host)。The IPCGRH register facilitates interrupts to
external hosts. Operation and use of the IPCGRH register is the same as
for other IPCGR registers. The interrupt output pulse created by the
IPCGRH register appears on device pin HOUT. The host interrupt
output pulse should be stretched. It should be asserted for 4 bootcfg
clock cycles (CPU/6) followed by a deassertion of 4 bootcfg clock
cycles. Generating the pulse will result in 8 CPU/6 cycle pulse blocking
window. Write to IPCGRH with IPCG bit (bit 0) set will only
generate a pulse if they are beyond 8 CPU/6 cycle period.
√ -- checks if the SRCSx bit of the IPCGRx
register is set
√ -- checks if the SRCSx bit of the IPCGRH
register is set
isInterruptAckSet
√ -- checks if the SRCCx bit of the IPCARx
register is set.
√ -- checks if the SRCCx bit of the IPCARH
register is set.
clearInterruptSource
√
√
isGEMInterruptSourceSet() returns 1 if the SRCCx bit
corresponding to the srcId is set in the IPCARx
register corresponding to the index specified.
如果与srcId对应的SRCCx位在与指定索引对应的IPCARx寄存器中被设置,则返回1。
CSL_IPC_clearGEMInterruptSource() clears the interrupt
source IDs by setting the SRCCx bit of IPCARx and
SRCSx bit of IPCGRx corresponding to the GEM index and
Source ID specified.
CSL_IPC_clearHostInterruptSource() function clears the
interrupt source IDs by setting the SRCCx bit of IPCARH
and SRCSx bit of IPCGRH corresponding to the Source ID
specified.
Error_init(&eb); //初始化错误块 Hwi_Params_init(¶ms); //初始化HWI对象 params.eventId = 90; //IPC INT /* Set the event ID of the associated host interrupt */ params.enableInt = TRUE; //打开中断
Hwi_create(5, &IpcIsr, ¶ms, &eb); //INT5 /* Create Hwi thread Hwi function is CpIntc_dispatch */ Hwi_enable(); //打开中断
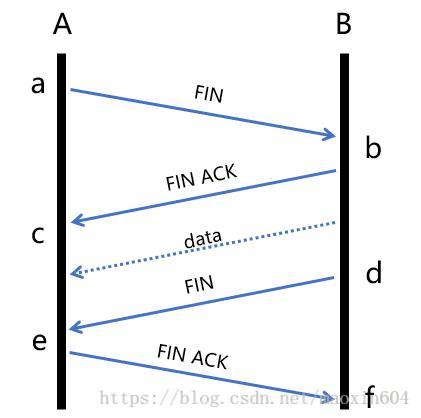
情况三:
比如,AB正常建立连接了,正在通讯时,A向B发送了FIN包要求关连接,B发送ACK后,网断了,A通过若干原因排查后放弃了这个连接(例如进程重启)。网通了后,B又开始发数据包,A收到后表示压力很大,不知道这野连接哪来的,就发了个RST包强制把连接关了,B收到后会出现connect
reset by peer错误。
Wireshark Tutorial
Wireshark是一款可以监听和捕捉网络通信数据的软件,对捕获的数据自下而上进行解码和分析至已知协议。如(Ethernet
II -- IP -- TCP 或 Ethernet II -- IP -- TCP -- HTTP)。
Capture Filters are used to filter out uninteresting packets already
at capture time. This is done to reduce the size of the resulting
capture (file) and is especially useful on high traffic networks or for
long term capturing.
Wireshark uses the pcap (libpcap/WinPcap) filter language for capture
filters. This language is explained in the tcpdump man page under
"expression" (http://www.tcpdump.org and search for "selects
which").
Note: This capture filter language is different from the one used for
the Wireshark display filters!
Example Ethernet: capture all traffic to and from
the Ethernet address 08:00:08:15:ca:fe
ether host 08:00:08:15:ca:fe
Example IP: capture all traffic to and from the IP
address 192.168.0.10
host 192.168.0.10
Example TCP: capture all traffic to and from the TCP
port 80 (http) of all machines
tcp port 80
Examples combined: capture all traffic to and from
192.168.0.10 except http
host 192.168.0.10 and not tcp port 80
Beware: if you capture TCP/IP traffic with the primitives "host" or
"port", you will not see the ARP traffic belonging to it!
Capture Filter Syntax
捕获过滤器标志
The following is a short description of the capture filter language
syntax. For a further reference, have a look at:
http://www.tcpdump.org/tcpdump_man.html
A capture filter takes the form of a series of primitive
expressions, connected by conjunctions (and/or) and optionally
preceded by not:
[not] primitive [and|or [not] primitive ...]
A primitive is simply one of the following:
[src|dst] host
This primitive allows you to filter on a host IP address or name. You
can optionally precede the primitive with the keyword
src|dst to specify that you are only interested in source
or destination addresses. If these are not present, packets where the
specified address appears as either the source or the destination
address will be selected.
ether [src|dst] host
This primitive allows you to filter on Ethernet host addresses. You
can optionally include the keyword src|dst between the
keywords ether and host to specify that you are only interested in
source or destination addresses. If these are not present, packets where
the specified address appears in either the source or destination
address will be selected.
gateway host
This primitive allows you to filter on packets that used host as a
gateway. That is, where the Ethernet source or destination was host but
neither the source nor destination IP address was host.
[src|dst] net [{mask }|{len }]
This primitive allows you to filter on network numbers. You can
optionally precede this primitive with the keyword src|dst
to specify that you are only interested in a source or destination
network. If neither of these are present, packets will be selected that
have the specified network in either the source or destination address.
In addition, you can specify either the netmask or the
CIDR(Classless Inter-Domain Routing) prefix
for the network if they are different from your own.
[tcp|udp] [src|dst] port
This primitive allows you to filter on TCP and UDP port numbers. You
can optionally precede this primitive with the keywords src|dst and
tcp|udp which allow you to specify that you are only interested in
source or destination ports and TCP or UDP packets respectively. The
keywords tcp|udp must appear before src|dst. If these are not specified,
packets will be selected for both the TCP and UDP protocols and when the
specified address appears in either the source or destination port
field.
less|greater
This primitive allows you to filter on packets whose length was less
than or equal to the specified length, or greater than or equal to the
specified length, respectively.
ip|ether proto
This primitive allows you to filter on the specified protocol at
either the Ethernet layer or the IP layer.
ether|ip broadcast|multicast
This primitive allows you to filter on either Ethernet or IP
broadcasts or multicasts.
relop
This primitive allows you to create complex filter expressions that
select bytes or ranges of bytes in packets. Please see the tcpdump man
pages for more details.
Capturing 捕获
This section will explain the capturing options and give hints on
what to do in some special cases.
Capture options 捕获设置
The capture options can be logically divided into the following
categories:
-input -filtering -stop conditions -storing -display while
capturing
Input options 输入设置
-Interface: You have to choose which interface
(network card) will be used to capture packets from. Be sure to select
the correct one, as it's a common mistake to select the wrong
interface.
-Link-layer header type: unless you are in the rare
case that you will need this, just keep the default.
Filtering options 过滤设置
-Capture packets in promiscuous mode: Usually a
network card will only capture the traffic to its own network address.
If you want to capture all traffic that the network card can "see", mark
this option. See the FAQ for some more details of capturing packets from
a switched network.
-Limit each packet to xy bytes: Will limit the
maximum size to be captured of each packet, this includes the link-layer
header and all subsequent headers. This can be useful when an error is
known to be in the first 20 bytes of a packet, for example, as the size
of the resulting capture file will be reduced.
-Capture Filter: Use a capture filter to reduce the
amount of packets to be captured. See "Capture Filters" in this help for
further information how to use it.
Storing options 存储设置
-File: You can choose the file to which captured
data will be written. If you don't enter something here a temporary file
will be used.
-Use multiple files: Instead of using a single
capture file, multiple files will be created. The generated filenames
will contain an incrementing number and the start time of the capture.
For example, if you choose "/foo.cap" in the "File" field, files like
"/foo_00001_20040205110102.cap", "/foo_00002_20040205110102.cap", ...
will be created. This feature can be useful if you do long term
capturing, as working with a single capture file of several GB usually
isn't very fast.
Stop condition options
终止设置
These three fields should be obvious; the capture process will be
automatically stopped if one of the selected conditions is exceeded.
Display while capturing
options
-Update list of packets in real time: Using this will show the
captured packets immediately on the main screen. Please note: this will
slow down capturing, so increased packet drops might appear.
-Automatic scrolling in live capture: This will scroll the "Packet
List" automatically to the latest captured packet, when the "Update List
of packets in real time" option is used.
-Name resolution: perform the corresponding name resolution while
capturing.
High performance
capturing 高性能模式捕获
When your network traffic is high, you might need to take some steps
to ensure Wireshark doesn't get behind on its capture, particularly if
you're running it on a slow computer.
When Wireshark cannot keep up, packets are dropped. To help avoid
this as much as possible:
Don't use the "Update list of packets in real time" option (see
above). This has a significant performance penalty.
Close other programs that might slow down your system, such as
virus scanner software, server processes, etc.
It might be a good idea not to use a capture filter. This will
depend on the task you have to do. As a rule of thumb: if you want to
see most of the packets and only filter a small number out, don't use a
capture filter (you can use a display filter later). If you only want to
capture a small proportion of the packets, it might be better to set a
capture filter, as this will reduce the number of packets that have to
be saved.
If you still get packet drops, it might be an idea to use a tool
dedicated to packet capturing and only use Wireshark for displaying and
analyzing the packets.
Have a look at tshark, the command line variant of wireshark, which
is included in this package. XXX: add a list of possibly useful
standalone capture programs.
Long term capturing 长期捕获
By "Long term capturing", it's meant to capture data from a network
for several hours or even days. Long term capturing will usually result
in huge capture files, being hundreds of MB's or even several GB's in
size!
Before doing a long term capture, get familiar with the options to
use for it, as you might not get what you desire. Doing a long term
capture not getting the results needed, is usually wasting a lot of
time. ;-)
Rules of thumb for this task: -Use the ring buffer feature when you
expect very large capture files. -Don't use the "Update list of packets
in real time" option. -Set an appropriate capture filter, when you are
only interested in some special packets from the net.
Display Filter 显示过滤器
Filtering
packets while viewing 观察时的过滤器组件
After capturing packets or loading some network traffic from a file,
Wireshark will display the packet data immediately on the screen.
Using display filters, you can choose which packets should (not) be
shown on the screen. This is useful to reduce the "noise" usually on the
network, showing only the packets you want to. So you can concentrate on
the things you are really interested in.
The display filter will not affect the data captured, it will only
select which packets of the captured data are displayed on the
screen.
Every time you change the filter string, all packets will be reread
from the capture file (or from memory), and processed by the display
filter "machine". Packet by packet, this "machine" is asked, if this
particular packet should be shown or not.
Wireshark offers a very powerful display filter language for this. It
can be used for a wide range of purposes, from simply: "show only
packets from a specific IP address", or on the other hand, to very
complex filters like: "find all packets where a special application
specific flag is set".
Note: This display filter language is different from the one used for
the Wireshark capture filters!
特殊字符
constains 和 matches
contains
用来判断是否包含一个值,matches
用来判断是否匹配一个表达式
Some common examples
一些通用示例
Example Ethernet: display all traffic to and from
the Ethernet address 08.00.08.15.ca.fe
eth.addr==08.00.08.15.ca.fe
Example IP: display all traffic to and from the IP
address 192.168.0.10
ip.addr==192.168.0.10
Example TCP: display all traffic to and from the TCP
port 80 (http) of all machines
tcp.port==80
Examples combined: display all traffic to and from
192.168.0.10 except http
ip.addr==192.168.0.10 && tcp.port!=80
Beware: The filter string builds a logical expression, which must be
true to show the packet. The && is a "logical and", "A
&& B" means: A must be true AND B must be true to show the
packet (it doesn't mean: A will be shown AND B will be shown).
Hint
Filtering can lead to side effects, which are sometimes not obvious
at first sight. Example: If you capture TCP/IP traffic with the
primitive "ip", you will not see the ARP traffic belonging to it, as
this is a lower protocol layer than IP!
WIRESHARK中的各种标志(TCP)
OUT OF ORDER
TCP Out-of-Order
正常情况:在TCP传输过程中,同一台主机发出的数据段应该是连续的,即后一个包的
Seq 号等于前一 个包的 Seq + Len
(三次握手和四次挥手是例外)。
正常情况:在TCP传输过程中,同一台主机发出的数据段应该是连续的,即后一个包的
Seq 号等于前一个包的 Seq + Len
(三次握手和四次挥手是例外)。
异常情况:如果Wireshark发现后一个包的
Seq 号大于前一个包的 Seq + Len
,就知道中间缺失了一段数据。假如缺失的那段数据在整个网络包中都找不到(即排除了乱序),就会提示TCP Previous segment not captured
。
TCP Previous segment lost - Occurs when a packet
arrives with a sequence number greater than the "next expected sequence
number" on that connection, indicating that one or more packets prior to
the flagged packet did not arrive. This event is a good indicator of
packet loss and will likely be accompanied by "TCP Retransmission"
events.
NETCTRL is used to initialize the stack and maintain services. To
accomplish this, it makes use of the configuration manager provided in
the NETTOOLS library. Note that the configuration definitions and
structures defined here are specific to NETCTRL, not CONFIG.
typedefstructaddrinfo { int ai_flags; // AI_PASSIVE, AI_CANONNAME, AI_NUMERICHOST int ai_family; // PF_xxx int ai_socktype; // SOCK_xxx int ai_protocol; // 0 or IPPROTO_xxx for IPv4 and IPv6 size_t ai_addrlen; // Length of ai_addr char * ai_canonname; // Canonical name for nodename _Field_size_bytes_(ai_addrlen) structsockaddr * ai_addr;// Binary address structaddrinfo * ai_next;// Next structure in linked list } ADDRINFOA, *PADDRINFOA;
defined in TI<socket.h>
IPv4套接字地址数据结构
1 2 3 4 5 6 7 8
// AF_INET family (IPv4) Socket address data structure. structsockaddr_in { UINT8 sin_len; // total length UINT8 sin_family; // address family UINT16 sin_port; // port structin_addrsin_addr; INT8 sin_zero[8]; // fixed length address value };
内核用地址存储数据结构
这个套娃里还有个套娃 in_addr
,这个结构体供内核调用,以储存更多地址数据。
1 2 3 4
// Structure used by kernel to store most addresses. structin_addr { UINT32 s_addr; // 32 bit long IP address, net order };
通用套接字地址储存数据结构
1 2 3 4 5 6 7 8 9
// Generic Socket address storage data structure. structsockaddr { UINT8 sa_len; // Length UINT8 sa_family; // address family char sa_data[14]; // socket data };
// Socket Oriented Functions SOCKET accept( SOCKET s, PSA pName, int *plen ); //接受一个套接字的连接 intbind( SOCKET s, PSA pName, int len ); //给套接字绑定一个名字 intconnect( SOCKET s, PSA pName, int len ); //在一个套接字上初始化连接 intgetpeername( SOCKET s, PSA pName, int *plen ); //在已连接的peer上返回名称地址 intgetsockname( SOCKET s, PSA pName, int *plen ); //返回套接字的本地名称地址 intgetsockopt( SOCKET s, int level, int op, void *pbuf, int *pbufsize ); //获取套接字设置信息 intlisten( SOCKET s, int maxcon ); //监听数据 intrecv( SOCKET s, void *pbuf, int size, int flags ); //接收数据 intrecvfrom( SOCKET s, void *pbuf, int size, int flags, PSA pName, int *plen ); //从指定对象处接收信息
intrecvnc( SOCKET s, void **ppbuf, int flags, HANDLE *pHandle ); // intrecvncfrom( SOCKET s, void **ppbuf, int flags, PSA pName, int *plen, HANDLE *pHandle ); voidrecvncfree( SOCKET Handle );
intsend( SOCKET s, void *pbuf, int size, int flags ); //发送信息 intsendto( SOCKET s, void *pbuf, int size, int flags, PSA pName, int len ); //在未连接的套接字上往指定目的地发送数据 intsetsockopt( SOCKET s, int level, int op, void *pbuf, int bufsize ); //设置套接字设置 intshutdown( SOCKET s, int how ); //关闭一半的套接字连接 SOCKET socket( int domain, int type, int protocol ); //创建套接字
SOCKET API IN CLIENT
第一步 创建套接字
SOCKET socket( int domain, int type, int protocol );
// // Select uses bit masks of file descriptors. These macros // manipulate handle lists. FD_SETSIZE can be modified as // needed. // #define FD_SETSIZE 16
int recv( SOCKET s, void *pbuf, int size, int flags );
pbuf 参数用于储存数据
size 为欲接收数据的大小
flags 为接收不到数据时的行为定义
FLAGS
CONDITIONS
MSG_DONTWAIT
Requests that the operation not block when no data is available
MSG_OOB
Requests receipt of out-of-band data that would not be received in
the normal data stream. Some protocols place expedited data at the head
of the normal data queue, and thus, this flag cannot be used with such
protocols.
MSG_PEEK
Causes the receive operation to return data from the beginning of
the receive queue without removing that data from the queue. Thus, a
subsequent receive call will return the same data.
MSG_WAITALL
Requests that the operation block until the full request is
satisfied. However, the call may still return less data than requested
if an error or disconnect occurs, or the next data to be received is of
a different type than that returned.
SOCKET API IN SERVER (LINUX
C)
第一步 创建套接字
1 2
int servSock; //Socket descriptor for server if( ( servSock = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP ) ) < 0 ) printf("socket() failed.\n");
A server daemon is a single network task that
monitors the socket status of multiple network servers.
When activity is detected, the daemon creates a task thread
specifically to handle the new activity. This is more efficient
than having multiple servers, each with their own listening
thread.
Type Socket type (SOCK_STREAM, SOCK_STREAMNC, or
SOCK_DGRAM) LocalAddress Local IP address (set to NULL for
wildcard) LocalPort Local Port to serve (cannot be NULL)
pCb Pointer to callback to handle server event (connection
or activity) Priority Priority of new task to create for
callback function StackSize Stack size of new task to
create for callback function Argument Argument (besides
socket) to pass to callback function MaxSpawn Maximum
number of callback function instances (must be 1 for UDP)
In the case of TCP, when a new connection is established, a new task
thread is created, and a socket session is opened. Then the user's
callback function is called on the new task thread, being supplied with
both the socket to the new connection and the caller specified argument
(as supplied to DaemonNew()). The callback function can keep the socket
and task thread for as long as necessary. It returns from the callback
once it is done with the connection. The function can choose to close
the socket if desired. The return code informs the daemon whether the
socket has been closed (0) or is still open (1).
NETCFG.H
CI means Configuration Item , and
CFG means Configuration .
Data-type UINT32 and IPN are both defined
in the header file <usertype.h> .
1 2
typedefunsignedint UINT32; typedef UINT32 IPN; // IP Address in NETWORK format
Structure CI_IPNET and structure CI_ROUTE
are different from each other.
The configuration is based on an active database. That is, any
change to the database can cause an immediate reaction in the system.
For example, if a route is added to the configuration, it is added to
the system route table. If the route is then removed from the
configuration, it is removed from the system route table.
配置存在激活与失效两种状态。
Configurations can be set active or inactive. When a
configuration is active, any change to the configuration results in a
change in the system. When a configuration is inactive, it behaves like
a standard database. Part of the main initialization sequence is to make
the system configuration active, and then inactive when shutting
down.
Both the configurations and configuration entries are referenced
by a generic handle. Configuration functions (named as
CfgXxx()) take a configuration handle parameter, while
configuration entry functions (name as CfgEntryXxx()) take
a configuration entry handle parameter. These handles are not
interchangeable.
Configuration entry handles are referenced. This means that each
handle contains an internal reference count so that the handle is not
destroyed by one task while another task expects it to stay valid.
Functions that return a configuration entry handle supply a referenced
handle in that its reference count has already been incremented for the
caller.
理论上句柄能够被无限持有,一旦释放则将被dereference。
The caller can hold this handle indefinitely, but should
dereference it when it is through.
IF 是指 Interface。ifconfig
是unix系统上的ip接口查看语句。而 CONFIGIF
是配置管理接口的意思。
// Defined Configuration Tags #define CFGTAG_OS 0x0001 // OS Configuration #define CFGTAG_IP 0x0002 // IP Stack Configuration #define CFGTAG_SERVICE 0x0003 // Service #define CFGTAG_IPNET 0x0004 // IP Network #define CFGTAG_ROUTE 0x0005 // Gateway Route #define CFGTAG_CLIENT 0x0006 // DHCPS Client #define CFGTAG_SYSINFO 0x0007 // System Information #define CFGTAG_ACCT 0x0008 // User Account
uint Item
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
// // Currently Used DHCP Compatible Items // Multiple instances are always to be stored as multiple config entries, not a concatenated byte string in a single config entry. // #define CFGITEM_DHCP_DOMAINNAMESERVER 6 // Stack's DNS servers #define CFGITEM_DHCP_HOSTNAME 12 // Stack's host name #define CFGITEM_DHCP_NBNS 44 // Stack's NBNS servers #define CFGITEM_DHCP_CLIENT_OPTION 61 // Stack DHCP Client Identifier
#define CFGITEM_SYSINFO_REALM1 256 // Realm Name 1 (max 31 chars) #define CFGITEM_SYSINFO_REALM2 257 // Realm Name 2 (max 31 chars) #define CFGITEM_SYSINFO_REALM3 258 // Realm Name 3 (max 31 chars) #define CFGITEM_SYSINFO_REALM4 259 // Realm Name 4 (max 31 chars) #define CFGITEM_SYSINFO_REALMPPP 260 // Realm Name PPP (max 31 chars) #define CFGITEM_SYSINFO_EVALCALLBACK 261 // Callback function to notify // application 5 min before // end of stack evaluation period
uint Mode
1 2 3 4
// Add Entry Flags #define CFG_ADDMODE_UNIQUE 0x0001 // Replace all previous instances #define CFG_ADDMODE_DUPLICATE 0x0002 // Allow duplicate data entry #define CFG_ADDMODE_NOSAVE 0x0004 // Don't include this entry in CfgSave
Socket in Windows
Windows Sockets可以保证应用程序在任何支持Windows Sockets API
的网络内正常通信。
In some cases where send() would block, it instead returns without
copying all of the data as requested.
In this case, the return value of send() indicates how many bytes
were actually copied. One example of this is if your program is blocking
on send() and then receives a signal from the operating system.
In these cases, it is up to caller to try again with any remaining
data.
套接字及流输入输出接口(IO)
TOPIC
文件描述符环境
文件描述符编程接口
套接字编程接口
元以太网套接字编程接口
全双工管道编程接口
因特网群组管理协议(IGMP)
在各嵌入式系统中,对文件描述符的支持都大相径庭。大部分情况,都只支持基本功能(bare
minimum functionality),
通常都以通用名称命名和提供被修剪过的函数(trimmed down support
functions)。
TI
NDK支持标准套接字接口函数,这些函数也要求文件描述符的支持,堆栈提供一个小型文件系统。
在堆栈代码内部的基本构建块是一个对象句柄。在其内部,套接字和管道都通过对象句柄寻址。然而,在应用层,套接字和管道都被当做文件描述符看待。文件描述符内涵附加状态信息(additional
state information),允许根据套接字活动阻塞和解除阻塞任务。
The stack library supports a handful of what are normally considered
file functions, so that sockets applications can be programmed in a more
traditional sense.
typedefstruct _fdpollitem { void *fd; //the fd or socket to check uint16_t eventsRequested; //a set of flags for requested events uint16_t eventsDetected; //a set of resulting flags for a detected event } FDPOLLITEM;
Only one version of an overloaded function can appear within the
extern C block. The code in the following example would result in an
error.
While you can use name overloading in your SYS/BIOS C++ applications,
only one version of the overloaded function can be called from the
configuration.
1 2 3 4
extern “C” { // Example causes ERROR Int addNums(Int x, Int y); Int addNums(Int x, Int y, Int z); // error, only one version of addNums is allowed }
structInvltem // Holdsdataforaninventoryitem { int partNum; // Part number string description; // Item description int onHand; // Units on hand double price; // Unit price }; // Function prototypes voidgetltemData(InvItem &); //普通引用,函数可能会对结构体数据造成影响
线程 是指程序的一个指令执行序列,WIN32
平台支持多线程程序,允许程序中存在多个线程。 在单 CPU 系统中,系统把 CPU
的时间片按照调度算法分配给各个线程,因此各线程实际上是分时执行的,在多
CPU 的 Windows NT 系统中, 同一个程序的不同线程可以被分配到不同的 CPU
上去执行。由于一个程序的各线程是在相同的地址空间运行的,因此设及到了如何共享内存,
如何通信等问题,这样便需要处理各线程之间的同步问题,这是多线程编程中的一个难点。